SpreadsheetLLM: Encoding Spreadsheets for Large Language Models

Spreadsheets have long been a fundamental tool in data management and analysis. However, their complex structures have posed significant challenges for AI systems, particularly large language models (LLMs). In a recent paper titled “SPREADSHEETLLM: Encoding Spreadsheets for Large Language Models”, Microsoft researchers have introduced a novel framework that aims to bridge this gap.
Research Paper: SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
The authors begin by highlighting the importance of spreadsheets, “Spreadsheets are ubiquitous for data management and extensively utilized within platforms like Microsoft Excel and Google Sheets” [Introduction]. However, they immediately point out the core challenge, “Understanding spreadsheet layout and structure, a longstanding challenge for traditional models, is crucial for effective data analysis and intelligent user interaction” [Introduction].
The Challenge of Spreadsheets for LLMs
The paper dives into why spreadsheets are particularly challenging for LLMs. The authors explain, “Spreadsheets pose unique challenges for LLMs due to their expansive grids that usually exceed the token limitations of popular LLMs, as well as their inherent two-dimensional layouts and structures, which are poorly suited to linear and sequential input” [Introduction]. This mismatch between the linear nature of LLM inputs and the two-dimensional structure of spreadsheets is a fundamental hurdle that the research aims to overcome.
Also, the researchers highlight an additional layer of complexity, “LLMs often struggle with spreadsheet-specific features such as cell addresses and formats, complicating their ability to effectively parse and utilize spreadsheet data” [Introduction]. This observation underscores the need for a specialized approach to enable LLMs to understand and work with spreadsheets effectively.
Introducing SPREADSHEETLLM
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
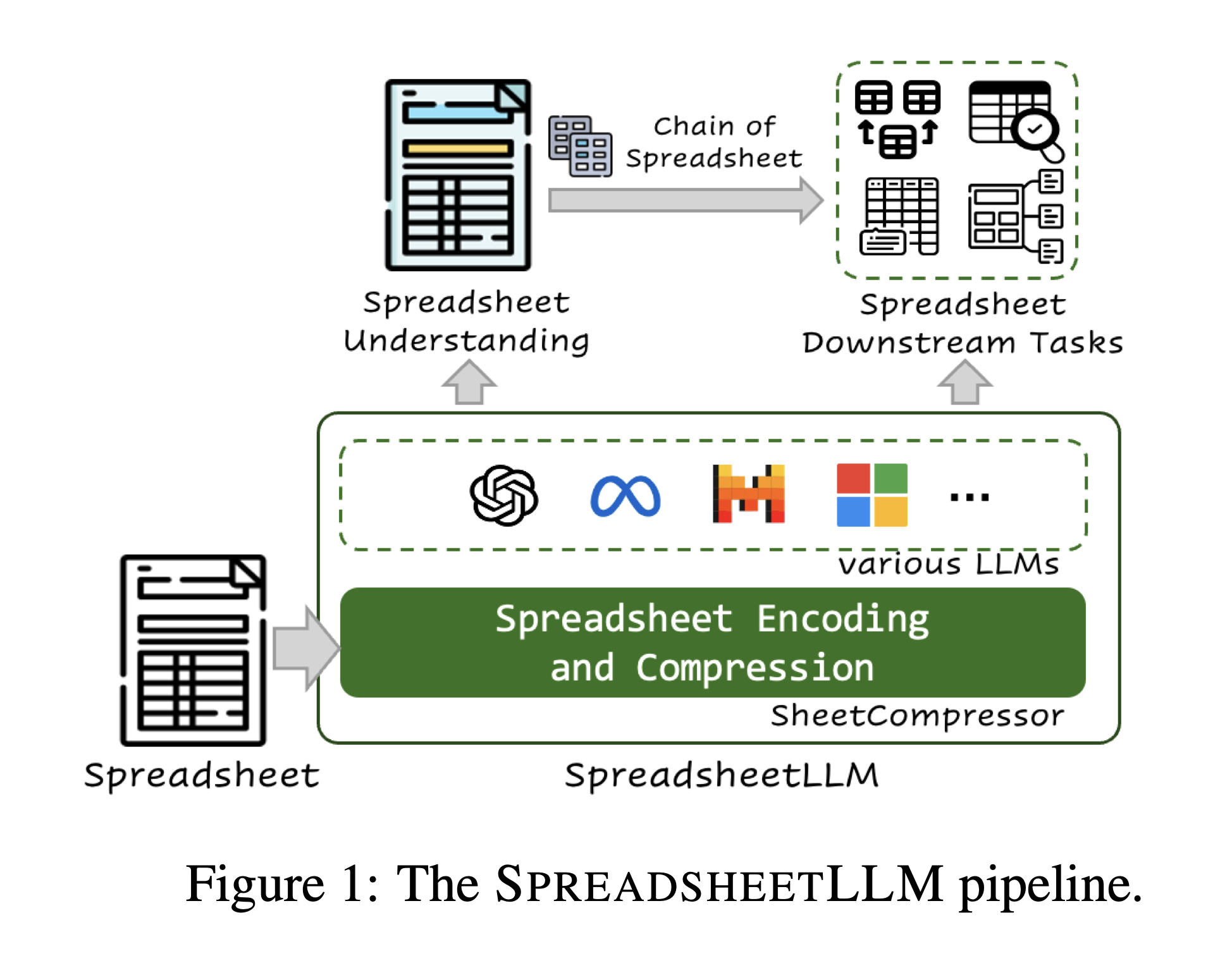
To address these challenges, the researchers developed SPREADSHEETLLM. They describe it as “a pioneering framework to unleash and maximize the potential of LLMs for spreadsheet understanding and reasoning” [Introduction]. This framework is built around a core component called SHEETCOMPRESSOR.
SHEETCOMPRESSOR is described as “an innovative encoding framework comprising three portable modules” [Introduction]. These modules are designed to work together to transform spreadsheets into a format that LLMs can process more effectively. Let’s examine each module in detail.
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
Structural Anchors for Efficient Layout Understanding
The researchers observed that “large spreadsheets often contain numerous homogeneous rows or columns, which contribute minimally to understanding the layout and structure” [Section 3.2]. To address this, they developed a method to identify what they call “structural anchors.”
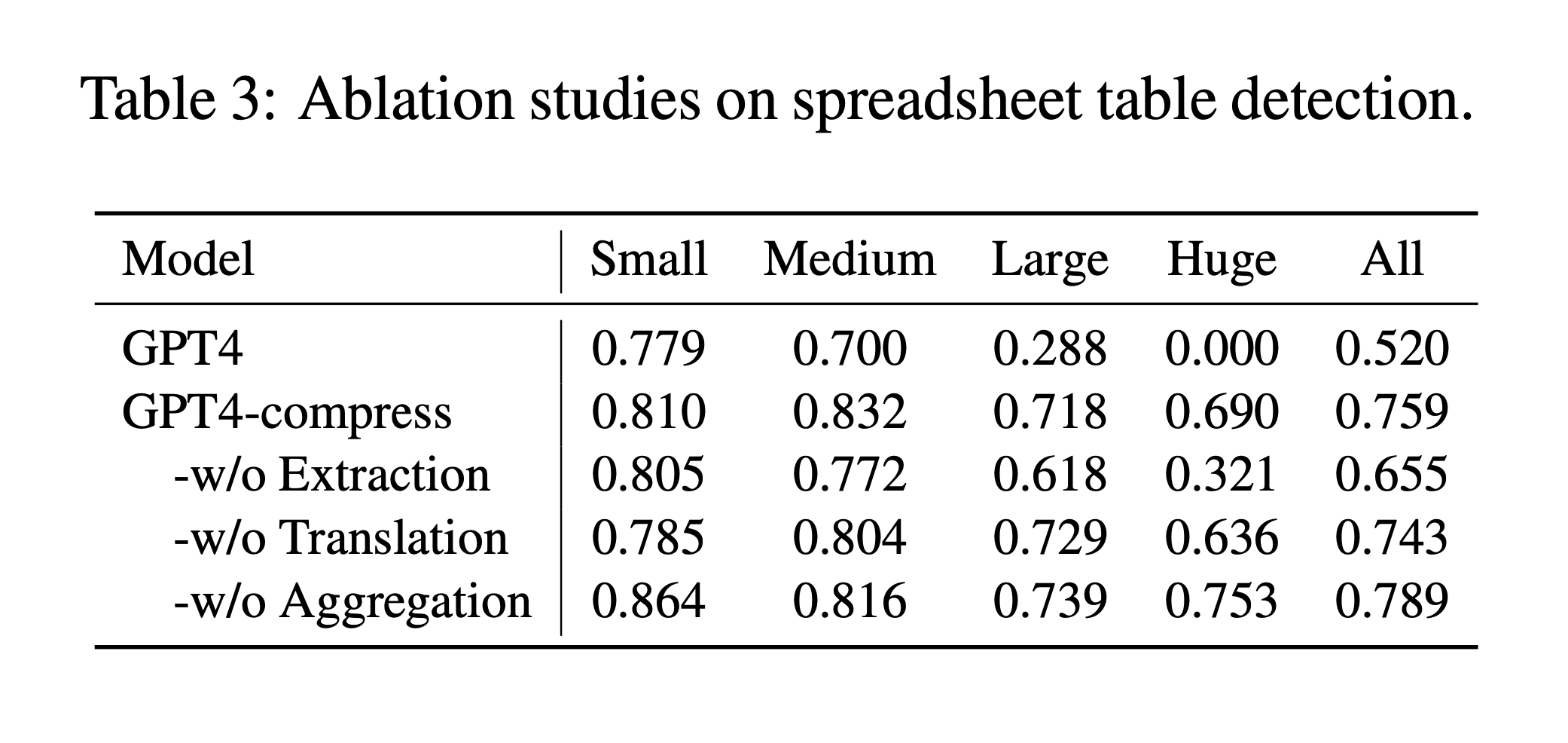
They explain, “We identify structural anchors—heterogeneous rows and columns at possible table boundaries that offer substantial layout insights” [Section 3.2]. This approach allows the model to focus on the most informative parts of the spreadsheet, significantly reducing data volume without losing required structural information.
The process is further detailed, “Using these anchor points, our method discards rows and columns that are located more than k units away from any anchor point, because they rarely serve as table boundaries” [Section 3.2]. This clever approach helps to maintain the required structure of the spreadsheet while reducing its size.
Inverted-Index Translation for Token Efficiency
The second module addresses the issue of token efficiency. The authors note, “Spreadsheets often contain numerous empty rows, columns, and scattered cells” [Section 3.3]. Their solution is a two-stage process they call “Inverted-index-based Translation.”
They describe the process, “The first stage involves converting the traditional matrix-style encoding into a dictionary format, where cell values serve as keys indexing the addresses. In the second stage, cells sharing the same value are merged, with empty cells excluded and cell addresses noted as ranges” [Section 3.3].
This approach is highly effective, as the researchers report, “Inverted-index Translation is a lossless compression method general for all spreadsheet understanding tasks, and it remarkably increases SHEETCOMPRESSOR’s compression ratio from 4.41 to 14.91” [Section 3.3].
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
Data-format-aware Aggregation
The third module focuses on handling numerical data more efficiently. The researchers observed that “adjacent cells typically share the same data format” [Section 3.4]. They argue that “the concrete numerical values are not essential for understanding the structure and semantics of the spreadsheet” [Section 3.4].
To leverage this insight, they introduce “Data-format-aware Aggregation for further compression and information integration” [Section 3.4]. This involves using “Number Format String (NFS), which is a built-in cell attribute in spreadsheets” [Section 3.4]. They also developed “a rule-based recognizer to map a cell value to a specific predefined data type” [Section 3.4].
The effectiveness of this approach is clear, “The compression ratio of the data regions also increases from 14.91 to 24.79” [Section 3.4].
Experiment Results and Performance
The researchers conducted extensive experiments to evaluate SPREADSHEETLLM’s performance. They focused on two main tasks, spreadsheet table detection and spreadsheet QA.
Spreadsheet Table Detection
For this task, the researchers used “the dataset introduced by (Dong et al., 2019b), a benchmark dataset of real-world spreadsheets with annotated table boundaries” [Section 4.1.1]. They further improved the quality of the test set, resulting in “a highly validated test set containing 188 spreadsheets” [Section 4.1.1].
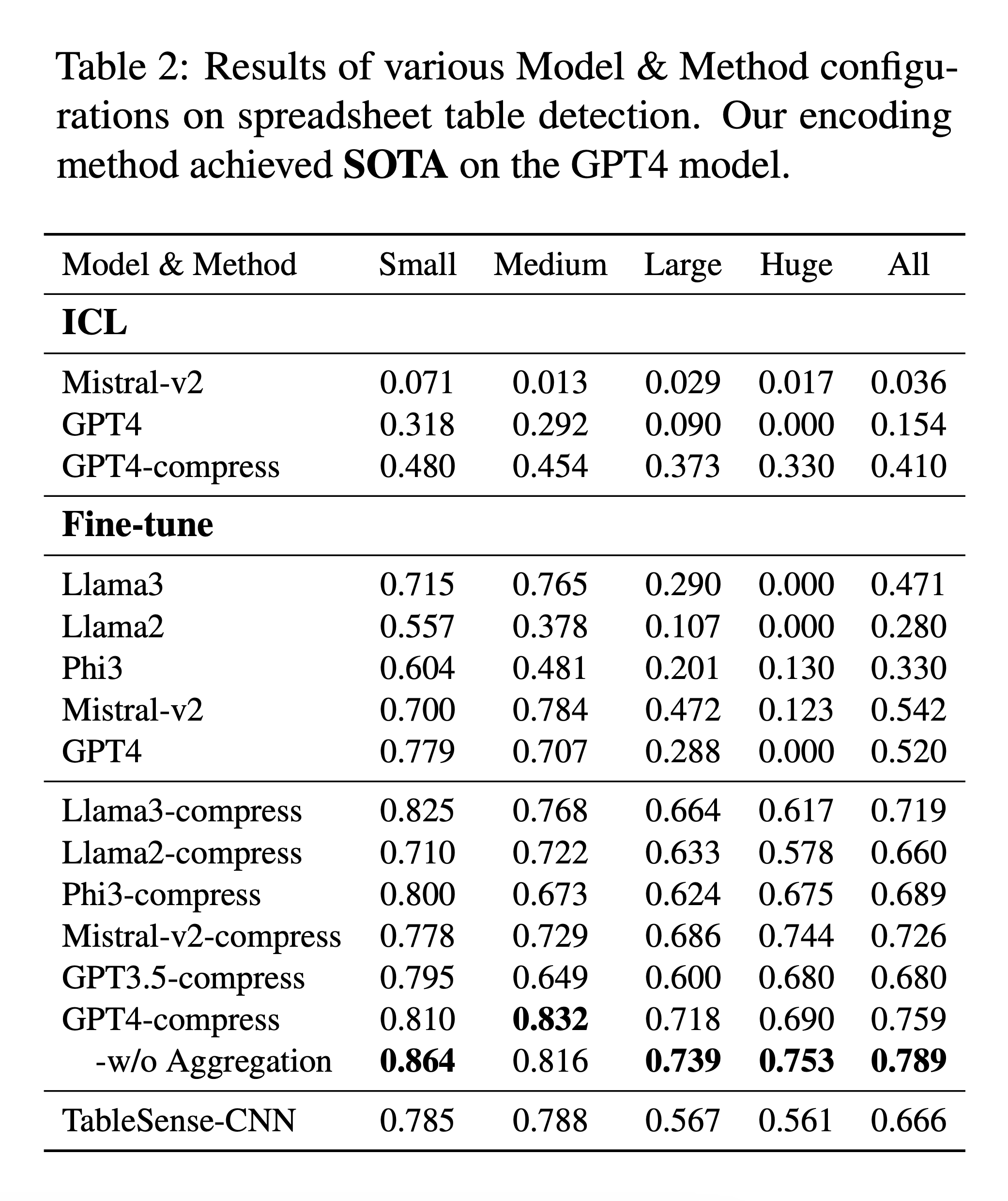
The results were impressive. They report, “The fine-tuned GPT4 model achieved the F1 score of approximately 76% across all datasets, while our encoding method without aggregation achieved the F1 score of approximately 79% across all datasets” [Section 5.2.1]. This represents “a 27% improvement over the same model fine-tuned on original data, a 13% increase over TableSense-CNN, and established a new SOTA” [Section 5.2.1].
Note that the benefits were particularly pronounced for larger spreadsheets. They note, “The improvements in F1 scores were particularly notable on huge spreadsheets (75% over GPT4, 19% over TableSense-CNN), large spreadsheets (45% and 17%), medium (13% and 5%), and small (8%) spreadsheets” [Section 5.2.1].
For more details, refer to the below tables.
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
Spreadsheet QA
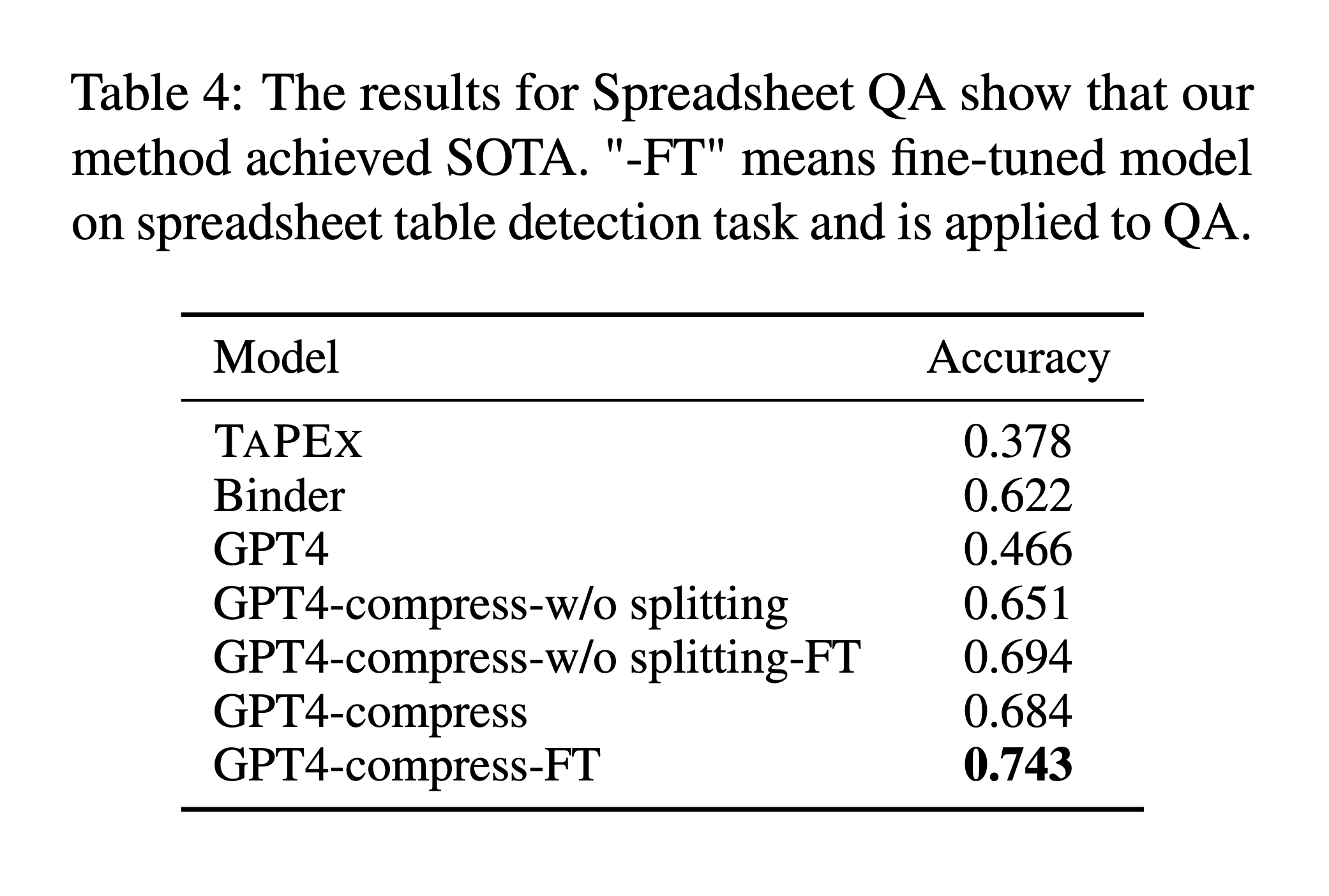
To evaluate the model’s ability to answer questions about spreadsheet data, the researchers developed a new dataset. They explain, “We sampled 64 spreadsheets from our larger collection and crafted 4-6 questions per spreadsheet, targeting fundamental operations such as searching, comparison, and basic arithmetic” [Section 4.2.1].
For this task, they introduced the Chain of Spreadsheet (CoS) method, which “includes two stages” [Section 4.2.3]. The results were again impressive, “The CoS method we developed significantly boosted the accuracy of models, showing a notable increase of 22% over the baseline GPT4 model” [Section 5.3].
For more details, refer to the below table.
 |
|---|
| https://arxiv.org/abs/2407.09025v1 |
Future Research
The development of SPREADSHEETLLM represents a significant leap forward in applying LLMs to structured data analysis. The authors highlight its broad applicability, “SPREADSHEETLLM is highly effective across a variety of spreadsheet tasks” [Conclusion].
However, they also acknowledge limitations and areas for future work. They note, “Currently, our methods do not yet harness spreadsheet format details such as background color and borders, because they take too many tokens” [Limitations]. They also suggest that “exploring advanced semantic compression techniques will be a key focus of our ongoing efforts to enhance the capabilities of SPREADSHEETLLM” [Limitations].
To conclude, SPREADSHEETLLM represents a significant milestone in the field of spreadsheet processing and analysis. By enabling LLMs to efficiently understand and reason about spreadsheet data, this framework has the potential to transform how we interact with and extract insights from spreadsheets.
The authors conclude by emphasizing the broad impact of their work: “SPREADSHEETLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs’ powerful understanding and reasoning capability on spreadsheets” [Introduction]. As this technology continues to evolve, we can expect even more powerful and user-friendly tools for spreadsheet analysis, potentially revolutionizing fields ranging from finance and business analytics to scientific research and data journalism.