Test-Time Training (TTT): A New Approach to Sequence Modeling
In artificial intelligence (AI) and natural language processing (NLP), sequence modeling is incredibly important. It’s the foundation for many applications we use every day, like language translation, text summarization, chatbots, and even code generation. However, the current popular methods for sequence modeling have some big challenges. New research by Sun et al. (2024) introduces an exciting solution called Test-Time Training (TTT) that could change everything.
Research Paper: Learning to (Learn at Test Time): RNNs with Expressive Hidden States
The Current Challenges in Sequence Modeling
To understand why TTT is so important, let’s first look at the problems with current methods:
- Recurrent Neural Networks (RNNs):
- Good: They’re fast and efficient, using less computer power.
- Bad: They struggle with long sequences, often forgetting important information from earlier in the text.
- Transformers:
- Good: They’re excellent at understanding long texts and finding connections between different parts.
- Bad: They need a lot of computer power, especially for very long texts, which can be slow and expensive.
The researchers highlight this trade-off, noting that “RNN layers have to compress context into a hidden state of fixed size” while “self-attention can also be viewed from the perspective above, except that its hidden state, commonly known as the Key-Value (KV) cache, is a list that grows linearly with t” [Section 2]. They further explain that “Self-attention can capture long-range dependencies, but scanning this linearly growing hidden state also takes linearly growing time per token” [Section 2].
Introducing Test-Time Training (TTT)
TTT is a clever new idea that aims to solve these problems. Here’s how it works:
- The Hidden State Becomes a Learner: In traditional models, the “hidden state” is just a bunch of numbers that carry information forward. In TTT, the hidden state is actually a small AI model that can learn and improve. As the paper states, “Our key idea is to use self-supervised learning to compress the historic context x₁, …, xₜ into a hidden state sₜ, by making the context an unlabeled dataset and the state a model” [Section 2.1]. The authors elaborate, “Concretely, the hidden state sₜ is now equivalent to Wₜ, the weights of a model f, which can be a linear model, a small neural network, or anything else” [Section 2.1].
- Learning During Use: Usually, AI models are trained once and then used without changing. TTT models continue to learn and adapt while they’re being used, helping them understand each specific text better. The researchers explain, “Even at test time, our new layer still trains a different sequence of weights W₁, …, Wₜ for every input sequence” [Section 2.1]. This dynamic adaptation is a key feature of TTT.
Self-Supervised Learning: The small AI model in the hidden state learns by trying to predict parts of the input text. This is called “self-supervised learning” because it doesn’t need humans to provide correct answers. The paper describes this as “a step of gradient descent on some self-supervised loss ℓ” [Section 2.1]. They provide an example of such a loss function:
ℓ(W; xₜ) = ∥f(x̃ₜ; W) - xₜ∥²
where x̃ₜ is a corrupted version of the input xₜ. [Section 2.1]
How TTT Works?
The researchers created two versions of TTT:
- TTT-Linear:
- Uses a simple linear model as the hidden state.
- It’s very fast and efficient.
- TTT-MLP:
- Uses a slightly more complex model called a Multilayer Perceptron (MLP).
- It can understand more complicated patterns but needs a bit more computer power.
Both versions work by continuously updating their understanding as they read through a text. The paper provides a detailed explanation of how this works, including mathematical formulas for the update rule and output rule [Section 2.1]:
Update rule:
Wₜ = Wₜ₋₁ - η ∇ℓ(Wₜ₋₁; xₜ)
Output rule:
zₜ = f(xₜ; Wₜ)
The authors also introduce a “mini-batch TTT” approach to improve efficiency: “We use
Gₜ = ∇ℓ(W’ₜ; xₜ)
where t’ = t - mod(t, b) is the last timestep of the previous mini-batch (or 0 for the first mini-batch), so we can parallelize b gradient computations at a time” [Section 2.4].
Why TTT is Important?
TTT offers several important advantages:
Better with Long Texts: Unlike RNNs, which tend to forget early parts of long texts, TTT keeps improving its understanding throughout the entire text. The researchers demonstrate this in Figure 2 (right),
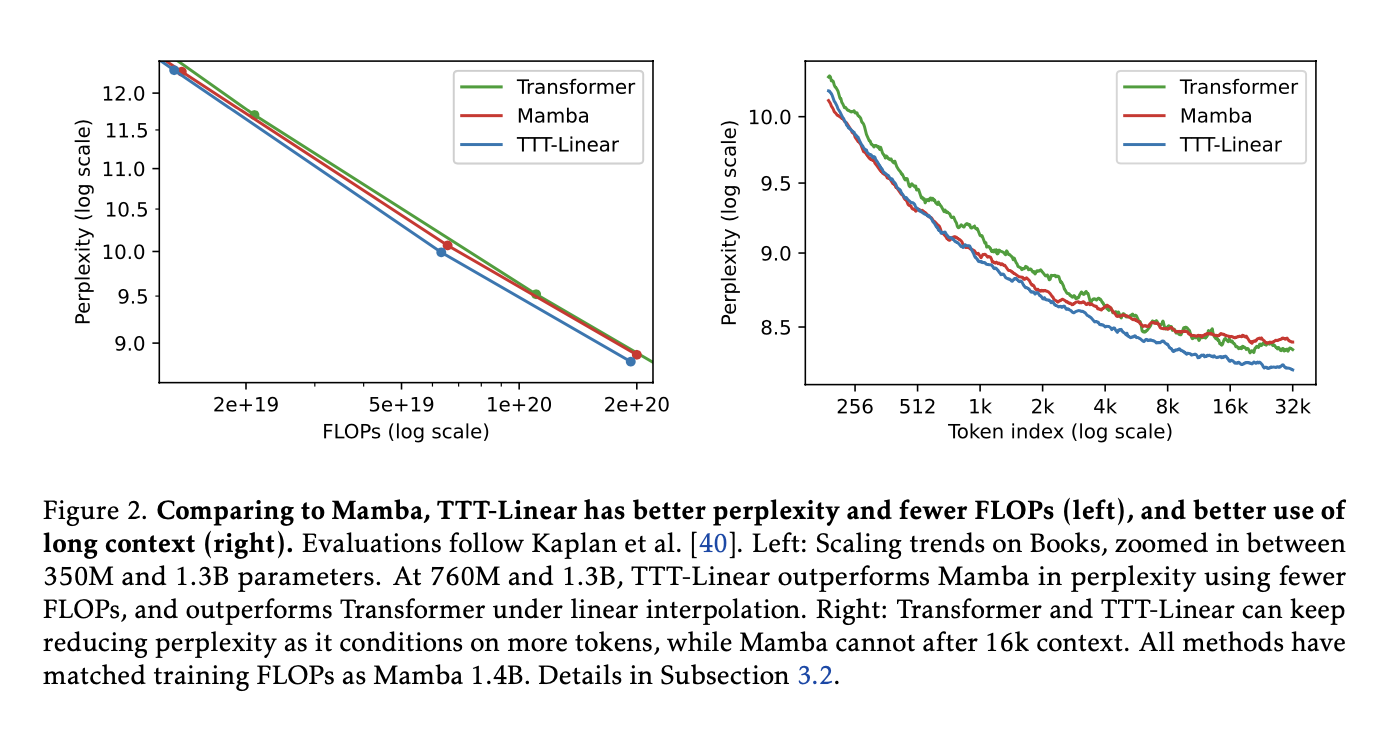
https://arxiv.org/abs/1706.03762 showing that “Transformer and TTT-Linear can keep reducing perplexity as it conditions on more tokens, while Mamba cannot after 16k context” [Section 1]. They further explain, “TTT layers can take advantage of their larger hidden states to compress more information in long context, where TTT-MLP outperforms TTT-Linear, which in turn outperforms Mamba” [Section 4.1].
Faster Than Transformers: For long texts, TTT-Linear can actually work faster than Transformers. The paper shows in Figure 3,
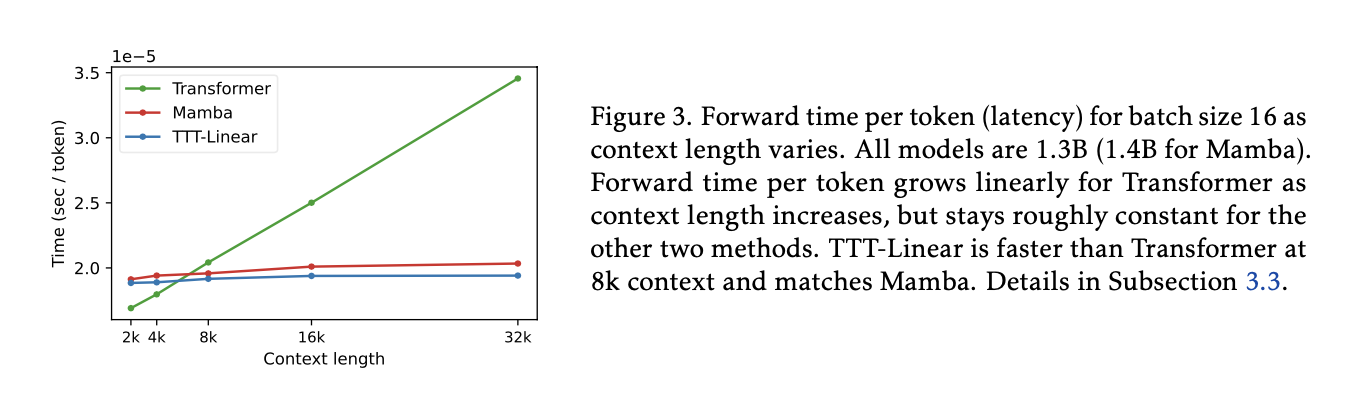
https://arxiv.org/abs/1706.03762 that “TTT-Linear is faster than Transformer at 8k context and matches Mamba in wall-clock time” [Section 1]. They achieve this efficiency through techniques like “mini-batch TTT and the dual form” [Section 2.5].
Flexible and Adaptable: The TTT approach isn’t just for text. The researchers believe it could be useful for other tasks that involve sequences, like understanding videos or controlling robots. They mention potential applications “such as robot manipulation and locomotion” [Section 4.2.1] and suggest that “for video tasks and embodied agents, whose context length can easily scale up to millions or billions, f could be a convolutional neural network” [Section 5].
How Well Does TTT Work?
The researchers tested TTT thoroughly:
- They built large AI models with up to 1.3 billion parameters.
- They compared TTT to top-performing Transformer models and a new type of RNN called Mamba.
- They used diverse datasets, including “The Pile” and “Books3”.
- They tested with different text lengths, from short paragraphs to very long documents.
The results were impressive:
TTT performed as well as or better than both Transformers and Mamba in most tests. As shown in Figure 11,
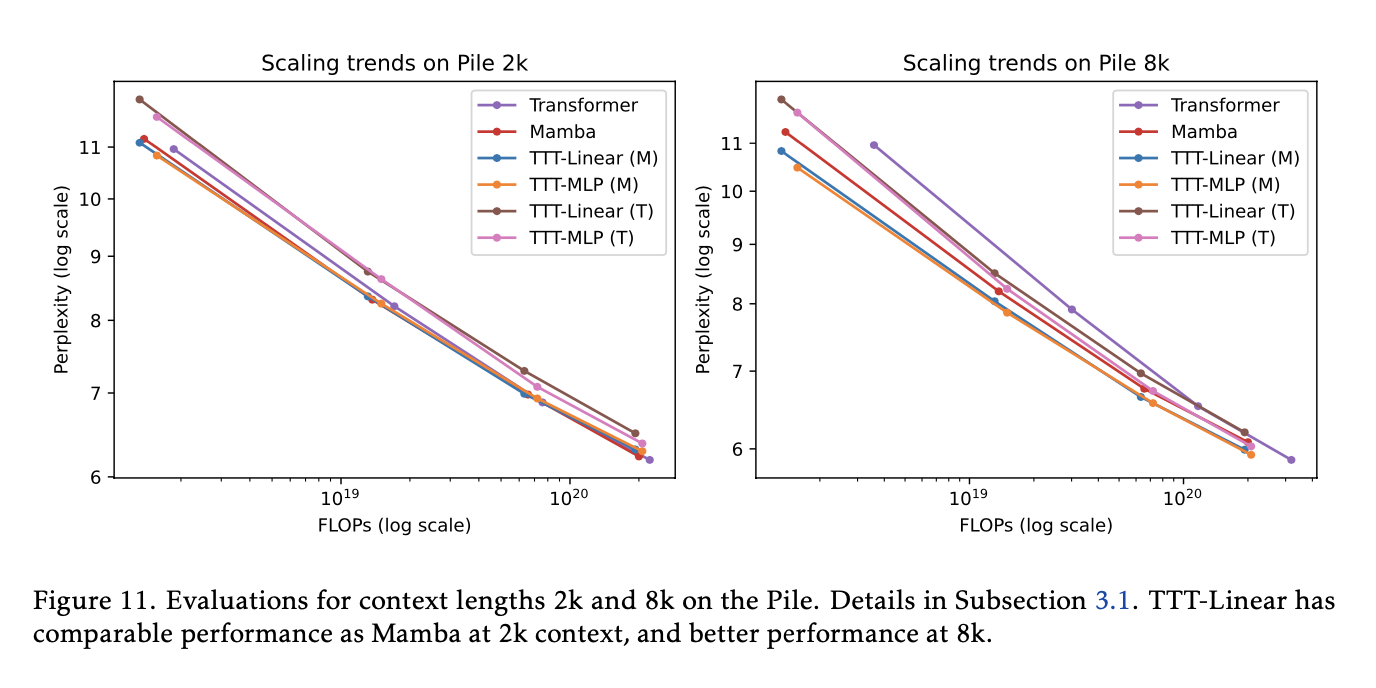
https://arxiv.org/abs/1706.03762 “TTT-Linear (M), Mamba, and Transformer have comparable performance” at 2k context, and “both TTT-Linear (M) and TTT-MLP (M) perform significantly better than Mamba” at 8k context [Section 3.1].
TTT was especially good with long texts, outperforming Mamba significantly. Figure 13,
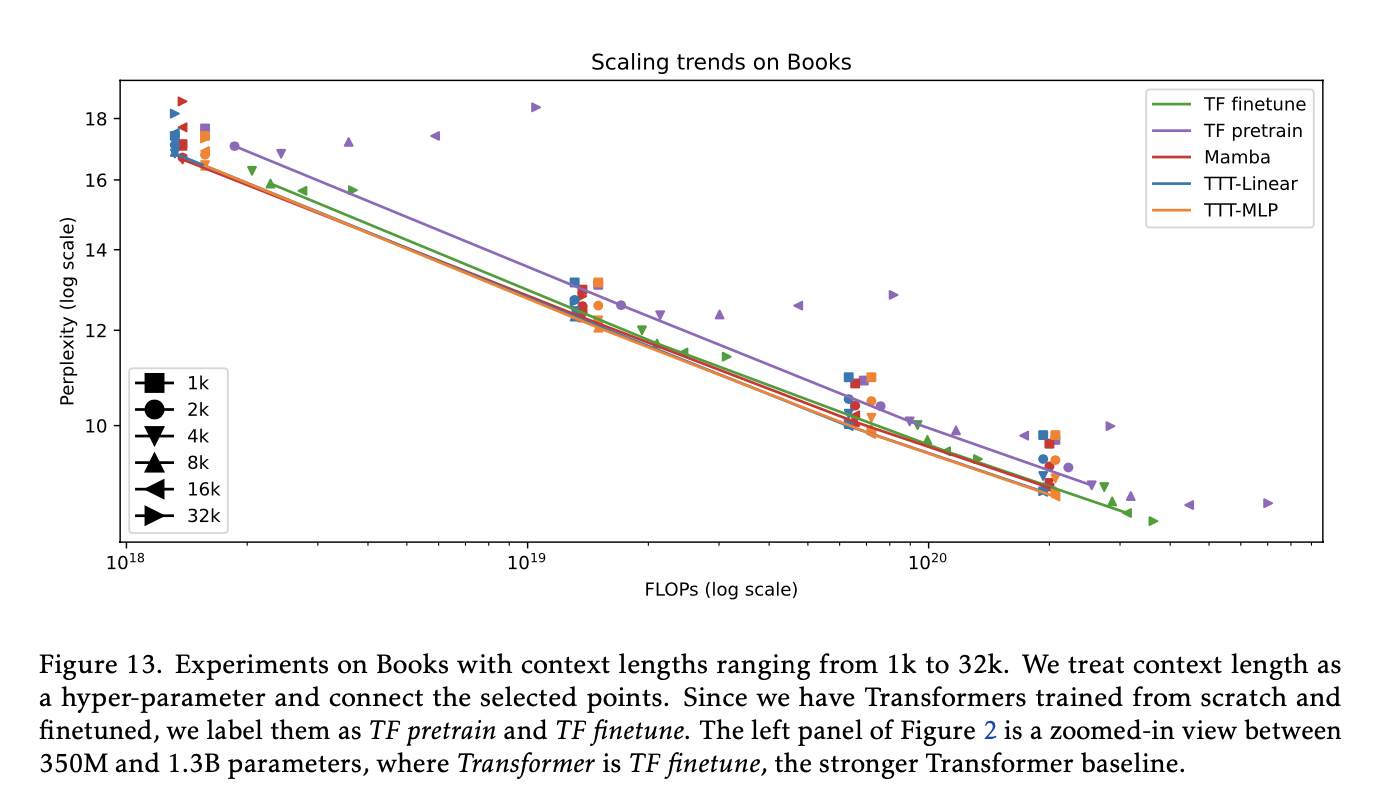
https://arxiv.org/abs/1706.03762 demonstrates this advantage across various context lengths [Section 3.2]. The authors note, “A robust phenomenon we observe throughout this paper is that as context length grows longer, the advantage of TTT layers over Mamba widens” [Section 3.1].
Further Challenges
While TTT shows a lot of promise, there are still some challenges:
- Memory Usage: TTT-MLP, the more complex version, needs a lot of computer memory. The researchers note that “TTT-MLP still faces challenges in memory I/O” [Section 1]. They acknowledge this as an area for future improvement.
- Further Improvements: The researchers suggest several ways TTT could be made even better:
- Trying new ways for the hidden state to learn from the text. They mention “more sophisticated formulations of the self-supervised task” [Section 2.3] and suggest that “There are many other ways to parameterize a family of multi-view reconstruction tasks, or perhaps a more general family of self-supervised tasks” [Section 5].
- Using more advanced AI models for the hidden state. They propose that “When context length becomes longer, f would also need to be larger” [Section 5].
- Testing TTT on other tasks beyond just understanding text. The authors are excited about the potential of TTT in various domains, stating, “For some of us, AI is a playground to probe about the nature of human intelligence” [Section 5].
In Conclusion, Test-Time Training (TTT) represents a big step forward in how AI can understand and work with text. By allowing AI models to learn and adapt while they’re being used, TTT opens up new possibilities for creating smarter, more efficient AI systems.
The researchers conclude that “TTT layers can take advantage of their larger hidden states to compress more information in long context” [Section 4.1], suggesting that this approach could lead to significant improvements in many areas of AI and NLP.
While there’s still work to be done, TTT has the potential to make AI better at understanding long and complex texts, while also being faster and more efficient than current methods. As the authors state, “We believe that human learning has a more promising connection with TTT, our inner loop, whose data is a potentially very long sequence with strong temporal dependencies, and any piece of data can be used for both training and testing” [Section 5].
The researchers are optimistic about the future of TTT, noting that “The search space for effective instantiations inside this framework is huge, and our paper has only taken a baby step” [Section 5]. They encourage further research in areas such as “Outer-loop parameterization,” “Systems optimization,” “Longer context and larger models,” and “More ambitious instantiations of f” [Section 5].
As research in this area continues, we can look forward to even more powerful AI systems that can tackle complex tasks and provide valuable insights into how we can make machines better at understanding and working with human language. The TTT approach may well be the key to unlocking the next generation of AI models that can truly understand and process long, complex sequences of information in a way that’s both efficient and effective.