Semantic Caching in RAG Applications

Imagine you’re running an application that uses a Large Language Model (LLM) like GPT-4, Anthropic Claude, etc. to answer customer questions. Every time a user asks something, your system sends a query to the LLM. Here’s the catch, each query costs money. Depending on use case, prices can range from $0.01 to $0.10 or more per query. This might not sound like much, but it adds up quickly:
- 1,000 queries per day = $10 to $100 daily
- 30,000 queries per month = $300 to $3,000 monthly
- 365,000 queries per year = $3,650 to $36,500 annually
For a growing business, these costs can become a significant expense. This is where semantic caching comes in as a cost saving option.
Semantic Caching
Semantic caching is like having a storage which stores previous conversations and can quickly recall relevant information. Here’s how it helps cut costs:
- Sometimes user questions are similar or repeated. Without caching, each question, even if it’s been asked before, triggers a new LLM query.
- Semantic caching identifies similar questions and reuses previous answers, avoiding unnecessary LLM calls.
- Let’s say 30% of incoming questions can be answered from the cache.
- In our earlier example of 30,000 monthly queries, that’s 9,000 queries we don’t need to send to the LLM.
- At $0.05 per query, that’s a saving of $450 per month or $5,400 per year!
Other Benefits
Semantic caching doesn’t just save money on LLM queries. It brings other benefits that indirectly improve performance of application.
- Cached responses are delivered almost instantly, improving user experience.
- For similar questions, users get consistent answers, which can reduce confusion and follow-up queries.
How Semantic Caching Works?
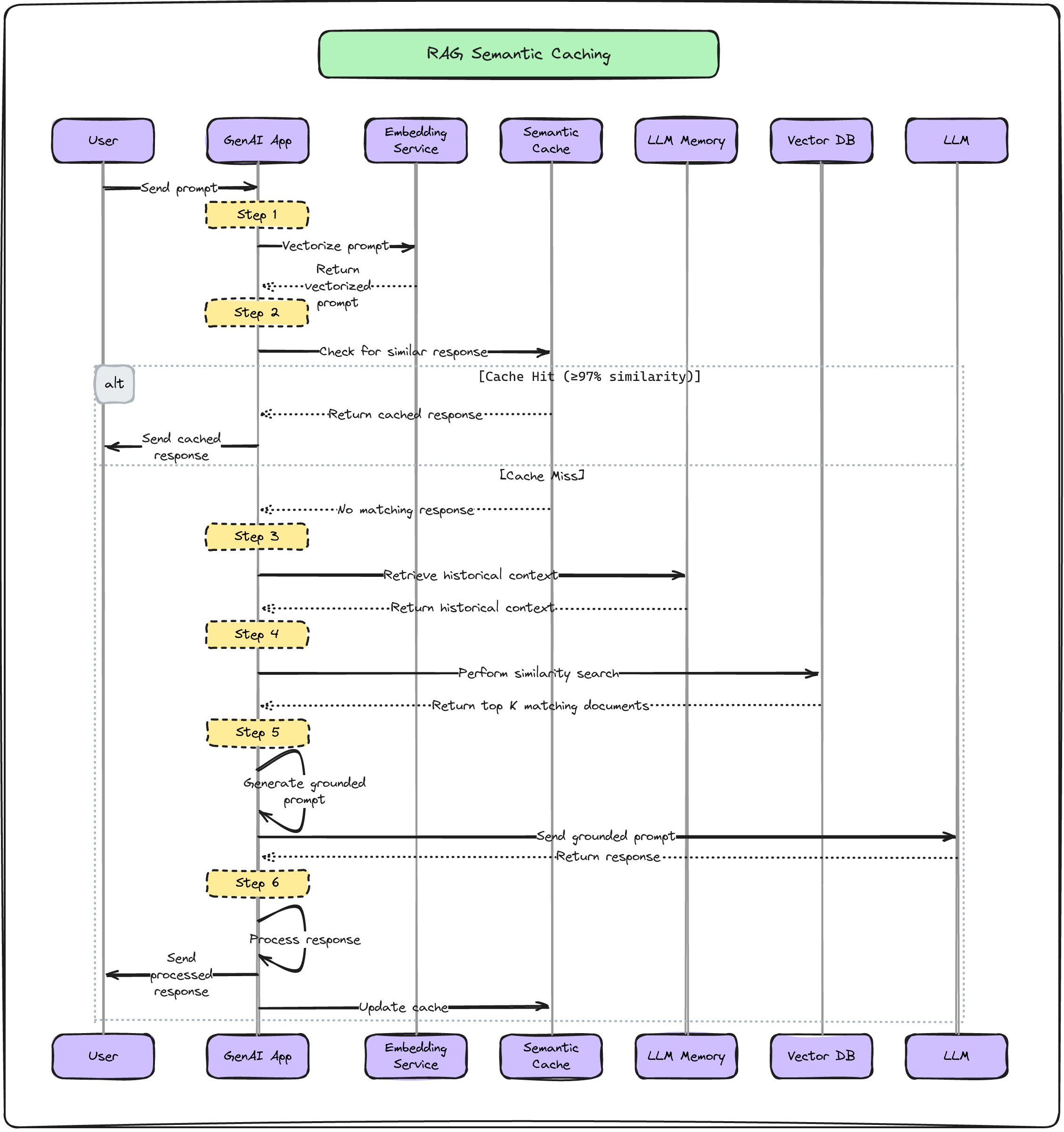
To understand the work flow of semantic caching take a look at the below diagram.
 |
|---|
| Semantic Caching Diagram |
Step-by-Step Explanation
- User type question into the system. This is called a “prompt.”
- The main part of the system called the GenAI App takes the question and convert it into a vector format. This is done by “Embedding Service.”
- The system first checks its cache memory to see if it has answered a very similar question before.
- If it finds a match that’s at least 97% similar, it will use that answer. This is called a “cache hit.”
- If it doesn’t find a close match, that’s called a “cache miss.”
- The system looks up some background information that might be helpful for answering the question. This comes from its “LLM Memory.”
- It also searches in Vector DB to find information that’s related to the question.
- The system takes all this information - the question, the background info, and the related context it found - and puts them together. This creates a “grounded prompt.”
- This grounded prompt is sent to a LLM (Large Language Model)
- The system takes the answer from the LLM and sends it back to user.
- At the same time, it adds this new question and answer to its semantic cache memory. This way, if someone asks a similar question in the future, the system can answer even faster.
To conclude, in the LLM-powered applications, where each query comes with a cost, semantic caching is helpful as a cost-saving tool. By reusing previous similar responses, it not only cuts direct expenses but also improves overall system performance and user satisfaction.