RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
The field of artificial intelligence has witnessed remarkable advances with large language models demonstrating exceptional capabilities across diverse tasks. However, these systems face significant limitations when tackling knowledge-intensive scenarios that require both access to external information and the ability to apply that information through structured reasoning processes. The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks [Abstract]. Despite its success, traditional RAG systems exhibit a critical weakness: existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning [Abstract].
The research paper “RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning” introduces a principled extension to the standard RAG framework that explicitly incorporates application-aware reasoning into the retrieval and generation pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference [Abstract]. This innovation represents a fundamental shift from passive knowledge access to active knowledge application, addressing a gap that has limited the effectiveness of RAG systems in complex reasoning tasks across mathematics, legal analysis, and medical diagnosis.
The core innovation of RAG+ lies in its dual corpus architecture, which maintains both a traditional knowledge base and a complementary application corpus. This application corpus contains examples that demonstrate the practical use of knowledge items through structured reasoning chains, worked examples, and step-by-step problem-solving procedures. During inference, the system retrieves not only relevant knowledge but also aligned application examples, providing large language models with both declarative information and procedural guidance.

The Limitations of Traditional RAG Systems
Knowledge Retrieval versus Knowledge Application
Traditional RAG systems operate under the assumption that providing large language models with relevant external knowledge is sufficient for generating accurate responses to complex queries. However, existing RAG methods often focus on lexical or semantic similarity when retrieving knowledge, paying little attention to how the retrieved content should be applied in downstream tasks [Section 1]. This approach succeeds admirably in factual recall tasks and open-domain question answering scenarios where the primary challenge involves locating and presenting information. However, while effective in factual recall and open-domain question answering, RAG frequently underperforms on domain-specific reasoning tasks [Section 1], where solving complex problems requires not merely access to information but understanding of how to manipulate and apply that information systematically.
The fundamental limitation comes from the cognitive gap between declarative knowledge and procedural knowledge. Declarative knowledge covers facts, definitions, and static information that can be explicitly stated and retrieved. On the other hand, Procedural knowledge involves understanding the processes, methods, and step-by-step procedures necessary to accomplish specific tasks. Traditional RAG systems are good at providing declarative knowledge but fail to bridge the gap to procedural application.
Consider a mathematical reasoning scenario where a model must solve a complex integration problem. A traditional RAG system might successfully retrieve the relevant integration rules and formulas. However, without examples demonstrating how to apply these rules in practice, including the sequence of steps, common pitfalls, and strategic decisions involved in the solution process, the model may struggle to produce correct solutions despite having access to the necessary theoretical knowledge.
The Cognitive Science Foundation
The limitations of traditional RAG systems become clearer when viewed through the lens of cognitive science research. This limitation reflects insights from educational psychology. Bloom’s Taxonomy identifies “applying” knowledge as a distinct cognitive skill that goes beyond simple recall [Section 1]. Bloom’s framework demonstrates that learners must progress through multiple cognitive levels: remembering facts, understanding concepts, and then applying knowledge in new situations. Traditional RAG systems primarily address the first two levels while neglecting the crucial application stage.
Similarly, cognitive architectures like ACT-R distinguish between declarative memory (facts) and procedural memory (skills), suggesting that coupling factual knowledge with procedural examples enhances performance on complex tasks [Section 1]. Research in cognitive psychology demonstrates that expertise in complex domains requires the integration of both memory systems. Experts possess not only extensive declarative knowledge but also well-developed procedural knowledge that enables them to apply their factual understanding effectively.
This cognitive science foundation explains why traditional RAG systems often underperform on procedural reasoning tasks despite having access to comprehensive knowledge bases. The systems lack the procedural components necessary to transform retrieved facts into actionable reasoning sequences.
Domain-Specific Challenges
The limitations of traditional RAG systems show differently across various domains, but common patterns emerge. In reasoning-centric domains such as mathematics, retrieving the right facts is only the first step. The model must also understand how to apply them to reach a specific goal [Section 2]. In mathematical domains, models may retrieve correct formulas but struggle with the strategic decisions involved in selecting appropriate solution methods or recognizing when specific techniques apply. Legal reasoning presents similar challenges, where models might access relevant statutes but fail to understand how legal precedents apply to novel factual scenarios.
Medical diagnosis exemplifies another domain where traditional RAG limitations become apparent. While a system might retrieve comprehensive information about symptoms and diseases, the diagnostic process requires understanding how to weigh evidence, consider differential diagnoses, and apply clinical reasoning patterns that experienced physicians develop through extensive practice.
These domain-specific challenges highlight the need for RAG systems that go beyond information retrieval to involve knowledge application. Our work addresses this gap by introducing an application-aware step that explicitly guides how retrieved knowledge is used [Section 2]. The patterns of reasoning, the strategic decisions, and the procedural steps that experts use in each domain represent essential components that traditional RAG systems fail to capture and provide to large language models.
The RAG+ Innovation: Application-Aware Reasoning
Theoretical Foundations
RAG+ addresses the fundamental limitations of traditional RAG systems by introducing application-aware reasoning as an explicit component of the retrieval-augmented generation process. Motivated by these insights, we propose RAG+, a simple yet effective extension to the RAG framework that enhances reasoning by bridging retrieval and generation with an application-aware stage [Section 1]. This innovation draws from multiple theoretical foundations, including cognitive psychology research on expertise development, educational theories about knowledge transfer, and computational approaches to reasoning in artificial intelligence systems.
Instead of retrieving only relevant knowledge, RAG+ additionally retrieves examples that demonstrate how the knowledge is applied in practice such as structured reasoning chains and stepwise solutions to ground the model’s output in task-relevant usage and to improve reasoning accuracy [Section 1]. The theoretical foundation rests on the understanding that effective reasoning requires both content knowledge and process knowledge. Content knowledge invloves the facts, principles, and concepts within a domain, while process knowledge involves understanding how to manipulate and apply content knowledge to solve problems. RAG+ operationalizes this distinction by maintaining separate but aligned repositories for content and process information.
The application-aware component of RAG+ reflects insights from research on how experts develop and apply domain knowledge. Expert performance in complex domains emerges not simply from knowing more facts but from developing sophisticated mental models that connect declarative knowledge with procedural patterns. These mental models enable experts to recognize problem types, select appropriate solution strategies, and execute complex reasoning sequences efficiently.
The Dual Corpus Architecture
The core innovation of RAG+ involves constructing a dual corpus architecture that maintains both knowledge and application components. RAG+ builds a dual corpus: one stores domain knowledge, and the other containing automatically generated application instances aligned to each fact [Section 1]. The knowledge corpus follows traditional RAG patterns, storing factual information, definitions, principles, and other declarative content. The application corpus represents the novel contribution, containing examples that demonstrate how knowledge items are applied in practice.
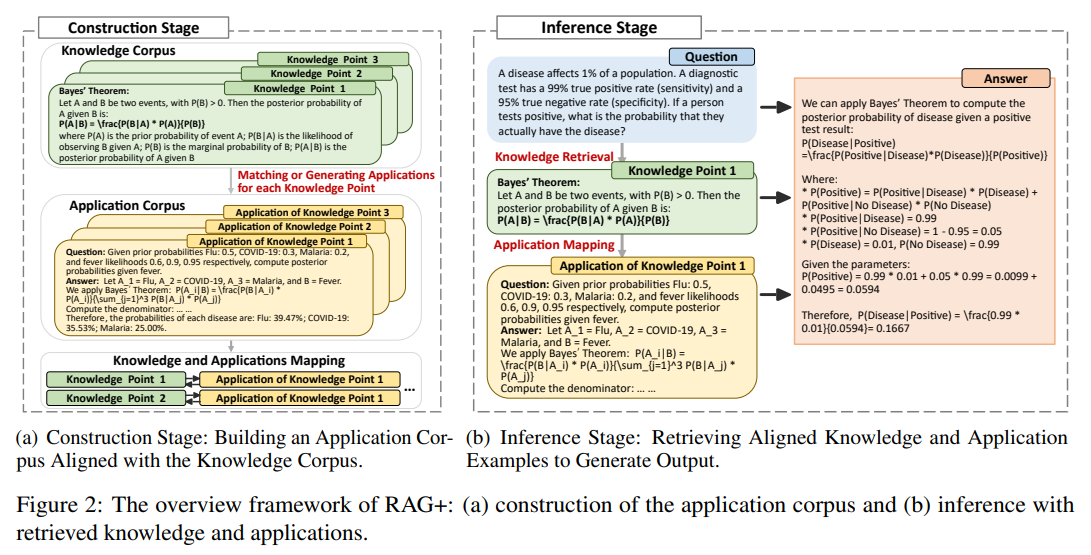
At inference time, the system retrieves relevant knowledge based on the input query and then fetches aligned application examples to provide practical context [Section 1]. The application corpus serves multiple functions within the RAG+ framework. First, it provides procedural templates that demonstrate how abstract knowledge translates into concrete problem-solving steps. Second, it offers strategic guidance about when and how to apply specific knowledge items. Third, it supplies contextual examples that help models understand the practical implications of theoretical principles.
This design encourages the model not only to recall facts but also to produce outputs that follow grounded reasoning patterns based on prior usage [Section 1]. The alignment between knowledge and application components represents a critical design feature of RAG+. Each knowledge item in the traditional corpus connects to one or more application examples that demonstrate its practical use. This alignment ensures that models receive both declarative information and procedural guidance during the retrieval process.
Knowledge Categorization and Application Generation
RAG+ uses a sophisticated approach to categorizing knowledge items and generating appropriate applications. We categorize knowledge items into two types based on their inherent nature to ensure generation of relevant and task-appropriate applications [Section 3.1]. The framework distinguishes between conceptual knowledge and procedural knowledge, recognizing that different types of knowledge require different forms of application examples.
Conceptual knowledge comprises static, descriptive information, such as definitions, theoretical explanations, or descriptions of entities and principles. The corresponding applications generally involve comprehension tasks, contextual interpretations, or analogies that elucidate meaning and deepen understanding [Section 3.1]. For conceptual knowledge, the application corpus contains examples that demonstrate comprehension, contextual interpretation, and practical understanding. These applications help models understand not just what concepts mean but how they apply in real-world scenarios.
Procedural knowledge refers to dynamic, actionable information including problem-solving strategies, inference rules, and step-by-step methods. Its associated applications are demonstrated through worked examples, reasoning chains, or practical problem-solving instances where the knowledge is actively applied [Section 3.1]. The corresponding applications for procedural knowledge involve worked examples, reasoning chains, and detailed demonstrations of how to execute specific procedures. These applications provide models with templates for applying procedural knowledge systematically.

Guided by the prior classification of knowledge items into conceptual and procedural types, we design tailored prompting strategies to elicit task-appropriate applications: comprehension or contextualization tasks for conceptual knowledge and worked examples or reasoning chains for procedural knowledge [Section 3.1]. The application generation process uses large language models to create appropriate examples for each knowledge item. This automated approach enables RAG+ to scale across large knowledge bases while maintaining consistency in the quality and format of application examples.
System Architecture and Implementation
Construction Stage: Building the Application Corpus
The RAG+ system operates through two distinct stages: construction and inference. The construction stage aims to build an application corpus aligned with an existing knowledge corpus [Section 3.1]. This process represents a significant departure from traditional RAG systems, which rely solely on existing knowledge bases without additional processing.
For each knowledge item k ∈ K, an application example a ∈ A is either retrieved or generated to demonstrate the practical use of k. These examples bridge the gap between passive knowledge access and task-oriented reasoning [Section 3.1]. The construction stage begins with analysis of the existing knowledge corpus to categorize items according to their type and content. This categorization process determines whether each knowledge item represents conceptual or procedural knowledge, which influences the type of application examples that will be generated or matched.
Depending on domain characteristics and data availability, we consider two complementary strategies for constructing application examples: application generation and application matching [Section 3.1]. For domains where authentic application examples exist, RAG+ employs an application matching strategy. This approach identifies real-world cases that naturally demonstrate the use of specific knowledge items. For example, in legal domains, court cases and legal precedents provide authentic examples of how specific statutes apply in practice. In mathematical domains, worked problems from textbooks and educational resources offer genuine demonstrations of how mathematical principles apply to specific problems.
To establish these pairings, we first perform category alignment by assigning both problems and knowledge items to broad categories using powerful LLMs with temperature sampling and self-consistency voting, followed by manual refinement to ensure accuracy [Section 3.1]. The application matching process involves multiple steps to ensure accurate alignment between knowledge items and application examples. Next, within each category, relevance selection is conducted by prompting the model to identify the most pertinent knowledge entries for each problem [Section 3.1].
For domains where authentic application examples are insufficient or unavailable, RAG+ employs automatic generation methods. The generation process uses powerful large language models to create application examples that demonstrate the practical use of specific knowledge items. The generation strategy adapts to the knowledge type, producing comprehension tasks for conceptual knowledge and worked examples for procedural knowledge.
Inference Stage: Joint Retrieval and Application
The inference stage represents the operational phase where RAG+ processes user queries by retrieving both knowledge and application examples. During inference, given a test query, RAG+ first retrieves relevant knowledge items from the knowledge corpus using any retrieval method (e.g., dense retrieval, reranking) [Section 3.2]. This stage distinguishes RAG+ from traditional RAG systems by incorporating application-aware components into the standard retrieval and generation workflow.
For each retrieved knowledge item k, its corresponding application example a, pre-aligned during the construction stage, is retrieved from the application corpus [Section 3.2]. The inference process begins with standard query processing, where the system analyzes the user input to understand the information requirements and reasoning demands. The retrieval component then searches the knowledge corpus using established methods such as dense retrieval or reranking approaches. This step produces a set of relevant knowledge items that address the factual requirements of the query.
The pair (k, a) is then incorporated into a predefined prompt template that guides the model with both factual information and procedural cues [Section 3.2]. The critical innovation occurs in the next step, where RAG+ retrieves application examples aligned with each selected knowledge item. This joint retrieval process ensures that the system provides both declarative information and procedural guidance. The application examples offer models concrete demonstrations of how the retrieved knowledge applies in practice.
RAG+ is retrieval-agnostic and can be seamlessly integrated into any existing RAG pipeline. Since the knowledge-application alignment is established offline, no modifications to retrieval or generation models are needed at inference [Section 3.2]. The modular design of RAG+ enables seamless integration with existing RAG pipelines. The system functions as a plug-and-play enhancement that can augment various RAG variants without requiring changes to underlying retrieval mechanisms or model architectures. This compatibility ensures that RAG+ can benefit from ongoing advances in retrieval technology while providing its application-aware enhancements.
Experimental Methodology and Results
Experimental Design and Domains
The RAG+ is evaluated across three reasoning-intensive domains: mathematics, medicine, and legal [Section 4.2]. These domains were selected because they require both factual knowledge and sophisticated reasoning processes, making them ideal test cases for application-aware enhancements.
The MathQA dataset is constructed from publicly available educational resources and is paired with a custom mathematical knowledge corpus [Section 4.2]. The mathematical domain focuses on numerical analysis problems that require understanding of computational methods, algorithmic procedures, and problem-solving strategies. The knowledge corpus contains mathematical definitions, theorems, and computational methods, while the application corpus includes worked examples demonstrating how these concepts apply to specific problems.
For legal, the sentencing prediction dataset from CAIL 2018 is used, with a knowledge corpus composed of statutes from the Criminal Law of China [Section 4.2]. The legal domain examines sentencing prediction tasks using data from the CAIL 2018 dataset, specifically focusing on Article 234 of Chinese Criminal Law concerning intentional injury cases. The knowledge corpus comprises legal statutes and regulations, while the application corpus contains examples of how these legal principles apply to specific case scenarios.
For medicine, the MedQA dataset is employed, together with a curated medical corpus from relevant to clinical reasoning [Section 4.2]. The medical domain employs the MedQA dataset to evaluate clinical reasoning capabilities. The knowledge corpus includes medical facts, diagnostic criteria, and treatment protocols, while the application corpus demonstrates how medical knowledge applies to specific clinical scenarios and diagnostic processes.
Baseline Comparisons and Model Variations
The experimental evaluation compares RAG+ against several representative RAG variants to assess the effectiveness of application-aware enhancements. To assess the effectiveness of the proposed RAG+ framework, we compare it against several representative RAG-based baselines, each embodying a distinct approach to utilizing retrieved information [Section 4.1]. The baseline methods include vanilla RAG, Answer-First RAG, GraphRAG, and Rerank RAG, representing different approaches to retrieval and generation within the RAG framework.
RAG is the standard framework that retrieves relevant documents based on the input query and generates responses conditioned on both the query and the retrieved content [Section 4.1]. Vanilla RAG serves as the fundamental baseline, implementing the standard retrieval-augmented generation approach where relevant documents are retrieved based on query similarity and incorporated into the generation process. Answer-First RAG (AFRAG) first generates a candidate answer from the query, which is then used to retrieve supporting evidence [Section 4.1]. Answer-First RAG employs a strategy where the model first generates a preliminary answer that guides subsequent retrieval of supporting evidence.
GraphRAG incorporates structured knowledge via knowledge graphs to facilitate multi-hop reasoning and improve contextual relevance [Section 4.1]. This approach represents attempts to enhance traditional RAG through structured representations rather than application-aware components. Rerank RAG re-ranks the top-k retrieved documents by a large language model and selects the top three for answer generation to enhance query-context alignment [Section 4.1]. This approach represents efforts to enhance retrieval quality within traditional RAG frameworks.
Nine conversational models from the Qwen, LLaMA, DeepSeek, and ChatGLM series were evaluated [Section 4.3]. This diverse model selection ensures that the results reflect the general effectiveness of application-aware enhancements rather than distinctive benefits for specific model architectures.
Performance Results Across Domains
The experimental results demonstrate consistent improvements from RAG+ across all evaluated domains and model configurations. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios [Abstract]. In the mathematical domain, RAG+ variants achieve improvements ranging from 2.5% to 7.5% over their non-augmented counterparts, with the most substantial gains observed for models that benefit from enhanced retrieval strategies.
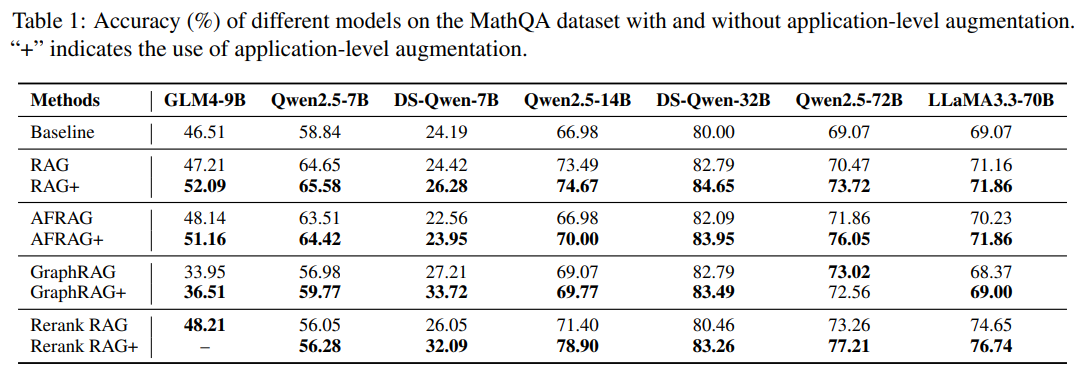
Notably, Qwen2.5-72B improves from 76.5% to 87.5% on legal prediction, and LLaMA3.3-70B rises from 78.2% to 86.5% on medical QA [Section 1]. The legal domain results show particularly impressive gains, with some models achieving over 10% improvement in accuracy. Qwen2.5-14B achieves a substantial improvement of over 7.5% with Rerank RAG+ [Section 5.1], while DS-Qwen-7B showing gains of 6.5% and 6.0% with GraphRAG+ and Rerank RAG+, respectively [Section 5.1]. These results demonstrate that application-aware augmentation provides significant benefits for complex reasoning tasks that require understanding of how legal principles apply to specific factual scenarios.
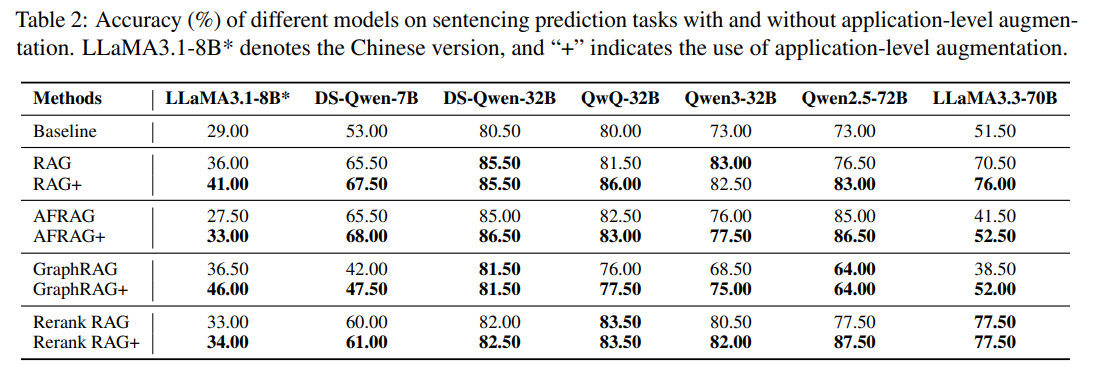
In the legal domain, Qwen2.5-72B achieves 87.5% accuracy with Rerank RAG+, a 10% gain over its non-augmented version [Section 5.2]. Medical domain evaluation reveals consistent but more modest improvements, with RAG+ variants typically achieving 2-4% gains over baseline methods. On the MedQA dataset, Rerank RAG+ yields the best performance for most models, especially the larger ones. For example, LLaMA3.3-70B reaches 85.6%, surpassing its baseline (81%) and Rerank RAG (81.0%) methods [Section 5.2].
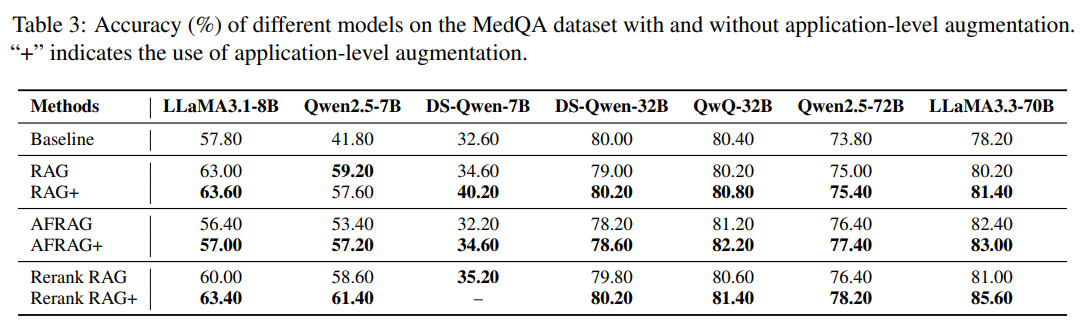
Even smaller models like DS-Qwen-7B benefit, demonstrating the broad effectiveness of application-aware augmentation [Section 1]. The results also reveal interesting patterns related to model scale and architecture. Larger models generally show more substantial benefits from application-aware augmentation, suggesting that sophisticated reasoning capabilities are necessary to fully utilize the procedural guidance provided by application examples. However, even smaller models demonstrate measurable improvements, indicating that the approach provides broad benefits across different model scales.
Scaling Effects and Model Analysis
The analysis of scaling effects reveals important insights about how application-aware augmentation interacts with model capabilities. All methods show consistent performance gains as model size increases from 7B to 14B and then to 72B, reflecting the enhanced reasoning capabilities of larger models [Section 5.3]. Experiments using Qwen2.5 models of different scales demonstrate that application-aware benefits increase with model size, suggesting that larger models can better utilize the sophisticated procedural guidance provided by application examples.
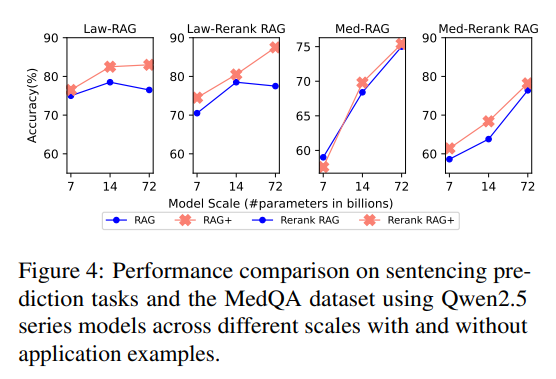
Notably, approaches augmented with application-level examples achieve larger improvements than their non-augmented counterparts [Section 5.3]. The scaling analysis also examines the impact of different retrieval strategies across model scales. In the legal domain, accuracy rises steadily with model scale when application augmentation is used [Section 5.3]. Rerank RAG+ consistently achieves the best performance for larger models, while simpler RAG+ variants provide substantial benefits for smaller models. This pattern suggests that the complexity of the retrieval strategy should match the reasoning capabilities of the underlying language model.
In the medicine domain, while all models benefit, the performance gains from scaling are less pronounced [Section 5.3]. The model analysis includes investigation of cross-model collaboration effects, where larger models enhance retrieval quality to support inference in smaller models. These results indicate that application-guided retrieval scales especially well with model size, further boosting knowledge integration and reasoning in complex, domain-specific tasks [Section 5.3]. These experiments demonstrate that using powerful models for reranking can significantly improve the effectiveness of application-aware augmentation for smaller models, highlighting opportunities for practical deployment strategies.
Case Studies and Qualitative Analysis
Mathematical Reasoning Case Study
The mathematical reasoning case study provides detailed examination of how RAG+ enhances problem-solving capabilities compared to traditional RAG approaches. The answer generated by RAG correctly identifies the interpolation method as Lagrange interpolation but fails to execute it accurately due to the complexity of intermediate symbolic expressions [Section 5.6]. The case involves finding a polynomial of degree 3 or less that passes through four specified data points, a problem that requires both knowledge of interpolation methods and understanding of how to apply these methods systematically.

While the approach is mathematically valid, errors in deriving the basis polynomials lead to an incorrect final result. In comparison, the Newton divided differences method, although less commonly emphasized in retrieval-based settings, provides a more transparent and step-by-step procedure [Section 5.6]. The traditional RAG response correctly identifies Lagrange interpolation as the appropriate method but fails to execute the procedure accurately due to errors in computing the basis polynomials. Despite having access to the correct theoretical knowledge, the model struggles with the complex symbolic manipulations required for implementation.
Its recursive computation of coefficients reduces algebraic errors and produces the correct polynomial [Section 5.6]. The RAG+ response demonstrates superior performance by applying Newton’s divided differences method, which the application corpus identified as providing more transparent step-by-step procedures. The application example guides the model through the recursive computation of coefficients, reducing algebraic errors and producing the correct polynomial solution.
This suggests that even when the correct method is retrieved, symbolic reasoning may fail due to execution errors, highlighting the need for verification mechanisms alongside retrieval [Section 5.6]. This case study illustrates several important principles about how application-aware augmentation enhances reasoning. First, the availability of multiple solution methods in the application corpus enables models to select approaches that are most suitable for their computational capabilities. Second, the step-by-step procedural guidance reduces execution errors that commonly occur in complex symbolic reasoning. Third, the application examples provide strategic insights about when different methods are most appropriate.
Legal Reasoning Analysis
The legal reasoning case study examines sentencing prediction tasks where models must apply criminal law statutes to specific factual scenarios. According to the facts of the case provided, the defendant Chen and others (including the minor Chen 2) participated in the attack on Liu with weapons (baseball bats) in a group conflict, resulting in Liu’s facial skin laceration reaching the level of first-degree minor injury [Figure 6]. The case involves determining appropriate sentencing for an intentional injury case that includes multiple aggravating and mitigating factors.

The traditional RAG response demonstrates knowledge of the relevant legal principles but fails to apply them systematically to the specific facts of the case. According to the facts of the case provided, the defendant Chen and others participated in the beating of Liu, causing Liu to suffer a minor injury of the first degree. However, in this case, Chen participated in the fight with weapons. Although Liu’s injuries have not yet reached the standard of serious injury, considering the circumstances of the armed fight, he should be punished more severely [Figure 6]. The model correctly identifies the basic sentencing guidelines but overlooks important factors such as the use of weapons and the presence of mitigating circumstances.
The RAG+ response shows more sophisticated legal reasoning by following the procedural patterns demonstrated in the application corpus. According to the information provided, Chen has the following circumstances that can be given a lighter punishment: 1. Chen was arrested by his father with the assistance of the public security organs, indicating that he did not have a strong desire to evade legal sanctions. 2. After being arrested, Chen truthfully confessed the facts of the crime and had a confession [Figure 6]. The model systematically considers aggravating factors such as armed assault while also accounting for mitigating circumstances like confession and cooperation with authorities. This comprehensive analysis leads to a more accurate sentencing recommendation that reflects proper application of legal principles.
The legal case study highlights how application examples provide essential procedural guidance for complex reasoning tasks. Therefore, combining knowledge with its applications produces the most effective results [Section 5.5]. Legal reasoning requires not only knowledge of statutes and precedents but also understanding of how to weigh evidence, consider competing factors, and apply legal principles systematically to novel factual situations.
Medical Diagnosis Case Study
The medical diagnosis case study focuses on a complex clinical scenario involving multiple symptoms and potential diagnoses. A 67-year-old man presents to his primary care physician for erectile dysfunction. He states that for the past month he has been unable to engage in sexual intercourse with his wife despite having appropriate sexual desire. He also endorses deep and burning buttock and hip pain when walking, which is relieved by rest [Figure 7]. The case requires integrating patient history, physical examination findings, and diagnostic test interpretations to reach accurate conclusions.
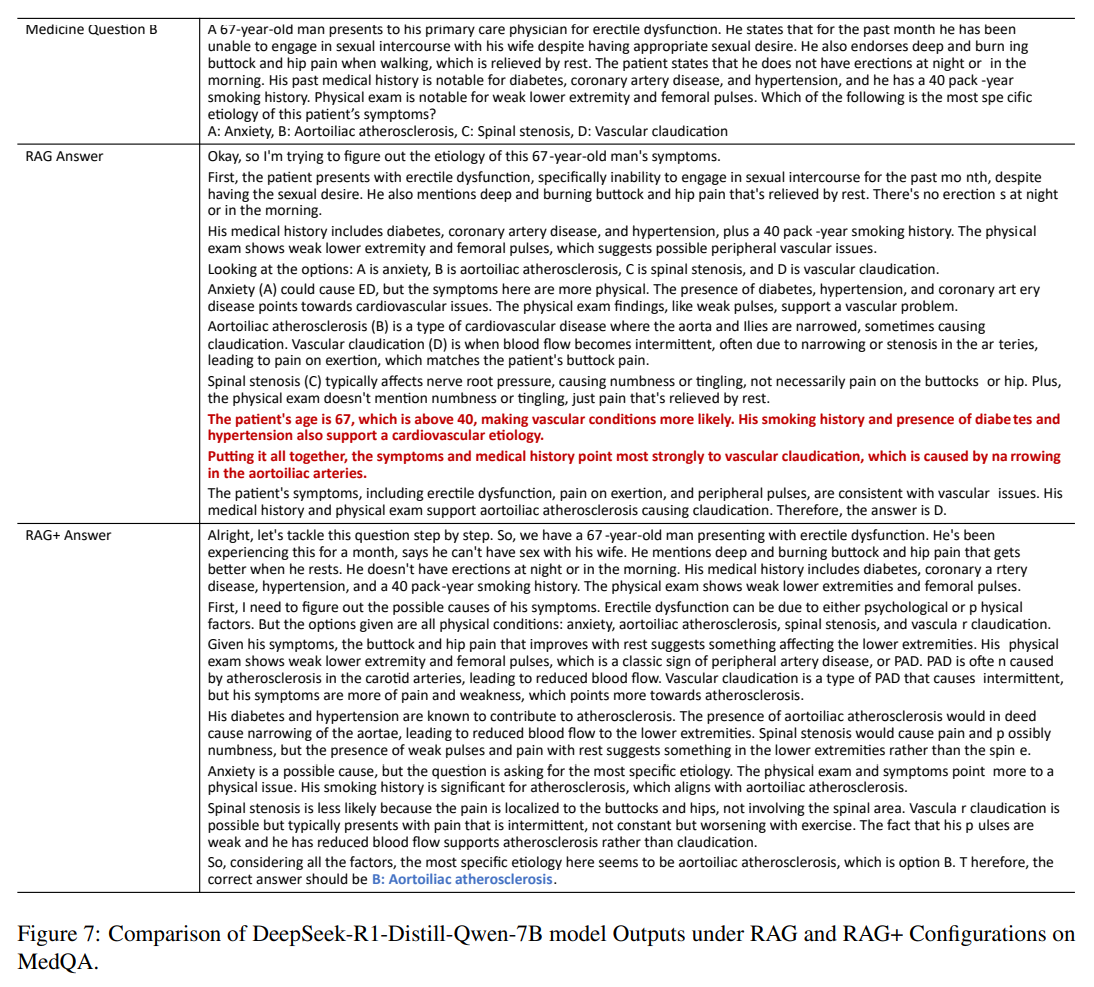
The patient states that he does not have erections at night or in the morning. His past medical history is notable for diabetes, coronary artery disease, and hypertension, and he has a 40 pack-year smoking history. Physical exam is notable for weak lower extremity and femoral pulses [Figure 7]. The traditional RAG response demonstrates access to relevant medical knowledge but struggles with the systematic application of diagnostic reasoning. The model identifies some relevant factors but fails to follow established diagnostic procedures or consider differential diagnoses systematically.
Given his symptoms, the buttock and hip pain that improves with rest suggests something affecting the lower extremities. His physical exam shows weak lower extremity and femoral pulses, which is a classic sign of peripheral artery disease, or PAD [Figure 7]. The RAG+ response exhibits more sophisticated clinical reasoning by following the procedural patterns demonstrated in the application corpus. His diabetes and hypertension are known to contribute to atherosclerosis. The presence of aortoiliac atherosclerosis would indeed cause narrowing of the aortae, leading to reduced blood flow to the lower extremities [Figure 7]. The model systematically considers patient risk factors, evaluates symptoms according to established criteria, and applies diagnostic reasoning frameworks to reach more accurate conclusions.
The medical case study illustrates how application-aware augmentation enhances clinical reasoning by providing procedural templates for diagnostic processes. So, considering all the factors, the most specific etiology here seems to be aortoiliac atherosclerosis [Figure 7]. Expert medical diagnosis requires not only extensive factual knowledge but also sophisticated procedural knowledge about how to integrate information, consider alternatives, and apply clinical reasoning systematically.
Limitations and Challenges
Construction Complexity and Resource Requirements
The RAG+ approach introduces significant additional complexity in the construction stage compared to traditional RAG systems. While RAG+ consistently improves performance, it also has several limitations. First, constructing a high-quality application corpus can be resource-intensive, especially in domains with limited annotated data [Section 7]. Building high-quality application corpora requires substantial computational resources and expertise in prompt engineering for application generation. Automated generation depends heavily on large language models, which may introduce errors or oversimplify complex reasoning [Section 7]. The automated generation process using large language models involves significant computational costs, particularly for domains with extensive knowledge bases.
The quality control process for generated applications presents ongoing challenges. While automated generation enables scaling across large knowledge bases, ensuring the accuracy and relevance of generated examples requires careful validation procedures. Manual review processes can become prohibitively expensive for large-scale deployments, while automated quality assessment methods may miss subtle errors or inappropriate examples.
To enable application-aware retrieval, we propose a lightweight method for constructing application-specific corpora from a knowledge base, typically generating one to two examples per item [Section 6]. The alignment process between knowledge items and application examples requires sophisticated matching algorithms and domain expertise. Generating the legal corpus with Qwen2.5-72B on eight 64 GB NPUs took around six hours, which is acceptable given this scale [Section 6]. Misalignment between knowledge and applications can lead to inconsistent or misleading guidance for language models, potentially degrading performance rather than improving it.
Knowledge-Application Alignment Challenges
The effectiveness of RAG+ depends critically on maintaining accurate alignment between knowledge items and application examples. Second, RAG+ assumes a strong alignment between knowledge and application pairs, but mismatches can occur - particularly when retrieved knowledge is noisy or incomplete - leading to incorrect or misleading reasoning [Section 7]. This alignment presents ongoing challenges, particularly when dealing with dynamic knowledge bases that require frequent updates or when working with domains where knowledge and applications evolve at different rates.
The alignment process becomes particularly challenging when knowledge items can apply to multiple different contexts or when application examples demonstrate the use of multiple knowledge items simultaneously. These many-to-many relationships require sophisticated indexing and retrieval strategies to ensure that models receive appropriate guidance.
The temporal alignment between knowledge and applications presents another challenge. Knowledge items may remain stable over time while application patterns evolve, or conversely, applications may remain relevant while underlying knowledge changes. Maintaining synchronization between these components requires ongoing maintenance and validation procedures.
Retrieval Quality and Efficiency Considerations
Finally, our current approach focuses on enhancing reasoning via application-level augmentation, but does not directly address retrieval quality or efficiency, which remain critical to overall performance [Section 7]. While RAG+ addresses limitations in knowledge application, it does not directly solve underlying retrieval quality issues that affect traditional RAG systems. Poor retrieval quality in the knowledge corpus can compound problems in the application corpus, leading to misaligned or irrelevant procedural guidance.
The corpus grows linearly with the number of items and introduces no retrieval overhead, as each item is directly paired with an application example [Section 6]. The joint retrieval process in RAG+ increases computational requirements compared to traditional RAG systems. Retrieving both knowledge and application components requires additional storage, indexing, and search operations that can impact system performance and scalability.
Final sizes reached 612 KB, 868 KB, and 105,558 KB, respectively, closely matching the sizes of the underlying knowledge corpora [Section 6]. The retrieval strategies must balance coverage and precision when selecting both knowledge and application components. Over-retrieval can overwhelm language models with excessive information, while under-retrieval may provide insufficient guidance for complex reasoning tasks.
Implications and Future Research
Advancing RAG Architecture Design
RAG+ outperforms baselines across tasks and RAG variants, highlighting the value of structured application in leveraging retrieved knowledge for reasoning [Section 7]. The success of RAG+ demonstrates the importance of incorporating procedural knowledge into retrieval-augmented generation systems. This insight suggests that future RAG architectures should explicitly consider both declarative and procedural components rather than focusing solely on factual information retrieval.
The dual corpus approach pioneered by RAG+ provides a template for developing more sophisticated RAG systems that address different types of knowledge requirements. Future work may explore more advanced application strategies and tighter integration to further enhance reasoning in LLMs [Section 7]. It might incorporate additional specialized corpora for different types of reasoning, such as causal reasoning, analogical reasoning, or creative problem-solving.
The modular design principles demonstrated by RAG+ enable incremental improvements to existing RAG deployments without requiring fundamental architectural changes. This compatibility facilitates adoption and experimentation with application-aware enhancements across different domains and use cases.
Integration with Emerging AI Paradigms
The RAG+ approach aligns with emerging trends toward more sophisticated AI reasoning capabilities. The integration of procedural knowledge components complements ongoing research into chain-of-thought reasoning, program synthesis, and tool-augmented language models.
Future developments might integrate RAG+ with autonomous agent frameworks, where application examples provide procedural templates for complex multi-step reasoning tasks. The combination of retrieval-augmented generation with agent-based reasoning could enable more sophisticated problem-solving capabilities.
The principles underlying RAG+ could extend to multimodal reasoning scenarios where visual, auditory, or other non-textual modalities require both declarative and procedural knowledge components. These extensions would enable more comprehensive reasoning across different types of information and task requirements.
The insights from RAG+ research have significant implications for educational technology and training applications. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs [Abstract]. The distinction between declarative and procedural knowledge components reflects fundamental principles in educational methods about how expertise develops and how knowledge transfers to new situations.
Educational applications could incorporate RAG+ principles to provide students with both factual information and procedural guidance for learning complex subjects. The application corpus approach could help students understand not just what they need to know but how to apply their knowledge effectively.
Professional training applications in domains such as medicine, law, and engineering could benefit from RAG+ approaches that provide both domain knowledge and procedural expertise. These applications could help practitioners develop both content knowledge and process skills necessary for expert performance.
Conclusion
The RAG+ framework represents a significant advancement in retrieval-augmented generation technology by addressing fundamental limitations in how traditional RAG systems handle complex reasoning tasks. In this work, we introduce RAG+, a framework that integrates application-level augmentation into retrieval-augmented generation [Section 7]. The core innovation of incorporating application-aware reasoning through dual corpus architecture demonstrates that effective knowledge-intensive reasoning requires both declarative information and procedural guidance.
Through comprehensive experiments across diverse domains and model scales, we demonstrate that incorporating application examples consistently leads to performance improvements [Section 7]. The experimental results across mathematical, legal, and medical domains provide compelling evidence that application-aware augmentation delivers consistent and substantial improvements over traditional RAG approaches. The improvements range from modest gains of 2-3% to substantial enhancements of 7-10%, depending on the domain complexity and model capabilities. These results demonstrate that the approach provides broad benefits across different reasoning contexts and model architectures.
The theoretical foundations underlying RAG+ connect artificial intelligence research with established principles from cognitive psychology and educational theory. Our results indicate that retrieval alone is insufficient - effective alignment and application of retrieved knowledge are crucial [Section 7]. The distinction between declarative and procedural knowledge components reflects fundamental insights about how expertise develops and how knowledge application differs from knowledge retrieval. This theoretical grounding suggests that the RAG+ approach addresses genuine cognitive requirements rather than only technical limitations.
The practical implementation of RAG+ demonstrates that sophisticated reasoning enhancements can be achieved through modular extensions that integrate with existing RAG infrastructure. This compatibility enables incremental adoption and experimentation without requiring fundamental changes to established systems or workflows.
The success of RAG+ opens several important research directions for advancing retrieval-augmented generation technology. Future work might explore more sophisticated application generation methods, dynamic alignment between knowledge and application components, and integration with emerging AI paradigms such as autonomous agents and multimodal reasoning systems.
The broader implications of RAG+ extend beyond technical improvements to encompass fundamental questions about how artificial intelligence systems can develop more human-like reasoning capabilities. The explicit incorporation of procedural knowledge components represents a step toward AI systems that not only access information but understand how to apply that information effectively in complex reasoning contexts.
As large language models continue to advance in capability and scale, the insights from RAG+ research will become increasingly important for developing systems that can tackle sophisticated real-world reasoning challenges. The framework provides a foundation for building AI systems that bridge the gap between information access and knowledge application, enabling more effective problem-solving across diverse domains and applications [Abstract].
The RAG+ approach ultimately demonstrates that advancing AI reasoning capabilities requires attention not only to the breadth and depth of available knowledge but also to the procedural mechanisms that enable effective knowledge application. This insight provides valuable guidance for developing the next generation of intelligent systems that can reason more effectively about complex problems and provide more reliable and actionable insights across critical application domains.
References
Research Papers
- Anderson, J. R., Bothell, D., Byrne, M. D., Douglass, S., Lebiere, C., & Qin, Y. (2004). An integrated theory of the mind. Psychological Review, 111(4), 1036-1060.
- Bloom, B. S. (1956). Taxonomy of Educational Objectives: The Classification of Educational Goals. Handbook I: Cognitive Domain. New York: McKay.
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., … & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
- Lin, X., Chen, X., Chen, M., Shi, W., Lomeli, M., James, R., … & Lewis, M. (2023). Ra-dit: Retrieval-augmented dual instruction tuning. In The Twelfth International Conference on Learning Representations.
- Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., … & Larson, J. (2024). From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130.
- Ruis, L., Grosse, R., & Nematzadeh, A. (2024). Procedural knowledge in pretraining drives reasoning in large language models. arXiv preprint arXiv:2411.12580.
- Krathwohl, D. R. (2002). A revision of Bloom’s taxonomy: An overview. Theory into Practice, 41(4), 212-218.
- Wang, Z., Zhao, S., Wang, Y., Huang, H., Xie, S., Zhang, Y., … & Yan, J. (2024). Re-task: Revisiting llm tasks from capability, skill, and knowledge perspectives. arXiv preprint arXiv:2408.06904.
- Xiong, G., Jin, Q., Lu, Z., & Zhang, A. (2024). Benchmarking retrieval-augmented generation for medicine. arXiv preprint arXiv:2402.13178.
- Xiong, G., Jin, Q., Wang, X., Fang, Y., Liu, H., Yang, Y., … & Zhang, A. (2025). Rag-gym: Optimizing reasoning and search agents with process supervision. arXiv preprint arXiv:2502.13957.
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query rewriting in retrieval-augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 5303-5315).
- Wang, L., Yang, N., & Wei, F. (2023). Query2doc: Query expansion with large language models. arXiv preprint arXiv:2303.07678.
- Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
- Zihao, W., Anji, L., Haowei, L., Jiaqi, L., Xiaojian, M., & Yitao, L. (2024). Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation. arXiv preprint arXiv:2403.05313.
- Jin, D., Pan, E., Oufattole, N., Weng, W. H., Fang, H., & Szolovits, P. (2020). What disease does this patient have? a large-scale open domain question answering dataset from medical exams. arXiv preprint arXiv:2009.13081.
- Xiao, C., Zhong, H., Guo, Z., Tu, C., Liu, Z., Sun, M., … & Xu, J. (2018). Cail2018: A large-scale legal dataset for judgment prediction. arXiv preprint arXiv:1807.02478.
- Qwen, T., Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., … & Qiu, Z. (2025). Qwen2.5 technical report. arXiv preprint arXiv:2412.15115.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
- Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., … & Yih, W. T. (2020). Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 6769-6781).
- Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., & Liu, Z. (2024). BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv preprint arXiv:2402.03216.
- Shi, F., Chen, X., Misra, K., Scales, N., Dohan, D., Chi, E. H., … & Zhou, D. (2023). Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning (pp. 31210-31227). PMLR.
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12, 157-173.
- Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., & Smola, A. (2023). Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923.
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
Technical Articles and Blogs
- What is RAG? - Retrieval-Augmented Generation AI Explained
- What Is Retrieval-Augmented Generation aka RAG
- What is retrieval-augmented generation (RAG)?
- Retrieval-Augmented Generation (RAG)
- Understanding RAG: 6 Steps of Retrieval Augmented Generation
- Retrieval Augmented Generation (RAG) for LLMs
- What is RAG (Retrieval Augmented Generation)?
- Retrieval Augmented Generation (RAG) in Azure AI Search
- Insights, Techniques, and Evaluation for LLM-Driven Knowledge Graphs
- How Do We Learn Complex Skills? Understanding ACT-R Theory
- Bloom’s Taxonomy of Learning - Domain Levels Explained
- Knowledge Representation in AI
- LLM Reasoning
- Adaptive Control of Thought - ACT-R
- Procedural Knowledge in Pretraining Drives LLM Reasoning