Retrieval Augmented Generation and Beyond

In recent years, Large Language Models (LLMs) have emerged as powerful tools in natural language processing, demonstrating remarkable capabilities across various tasks. However, these models often face significant limitations when it comes to domain-specific knowledge, up-to-date information, and factual accuracy. To address these challenges, researchers have been exploring ways to augment LLMs with external data sources. This article delves into the concept of data-augmented LLMs, with a particular focus on Retrieval-Augmented Generation (RAG) and related techniques, based on the comprehensive survey paper “RAG and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely.”
If you are not comfortable reading entire article, please take a look at podcast below and shout out to Google Gemini for its 🤯🤯🤯 capabilities.
The need for data-augmented LLMs arises from several key limitations of standalone models. Despite their impressive capabilities, LLMs struggle with temporal relevance, as their knowledge is based on training data that can quickly become outdated, especially in rapidly evolving fields. They also often lack specialized knowledge required for specific industries or scientific domains. Perhaps most concerningly, LLMs can sometimes generate plausible-sounding but factually incorrect information, a phenomenon known as “hallucination.” Additionally, controlling and interpreting the outputs of these models can be challenging, making it difficult to guide them to use specific information or explain their reasoning process.
Data-augmented LLMs aim to address these limitations by incorporating external data sources during the inference process. This approach offers several significant advantages, as highlighted in the research paper. “Data augmented LLM applications have demonstrated advantages over applications built solely on generic LLMs” (Introduction) in several key aspects.
Firstly, they offer “Enhanced Professionalism and Timeliness” by providing “more detailed and accurate answers for complex questions, allowing for data updates and customization.” This ensures that the model’s responses are grounded in current information, crucial for rapidly changing fields.
Secondly, they enable better “Alignment with Domain Experts” by leveraging domain-specific data, allowing the models to “exhibit capabilities more like domain experts, such as doctors and lawyers.” This dramatically expands the potential applications of LLMs in specialized fields.
Thirdly, data-augmented LLMs contribute to a “Reduction in Model Hallucination” by “generating responses based on real data, grounding their reactions in facts and significantly minimizing the possibility of hallucinations.”
Finally, they offer “Improved Controllability and Explainability” as “the data used can serve as a reference for the model’s predictions, enhancing both controllability and explainability.” This last point is particularly crucial for building trust in AI systems, especially in high-stakes applications.
 |
|---|
| https://arxiv.org/abs/2409.14924 |
To formalize the concept of data-augmented LLMs, the research paper presents a clear problem definition. “Data-augmented LLM applications can be formulated as follows:
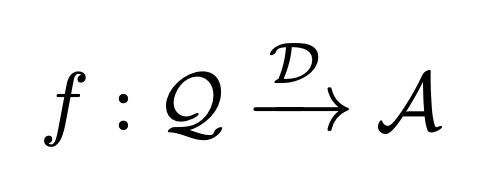 |
|---|
| https://arxiv.org/abs/2409.14924 |
where Q, A, and D represent the user’s input (Query), the expected response (Answer), and the given data, respectively.” (Problem Definition) This formulation elegantly captures the essence of these systems: creating a function that maps user queries to answers based on external data. The goal is to develop a system that can effectively utilize the external data (D) to produce accurate and relevant answers (A) to user queries (Q).
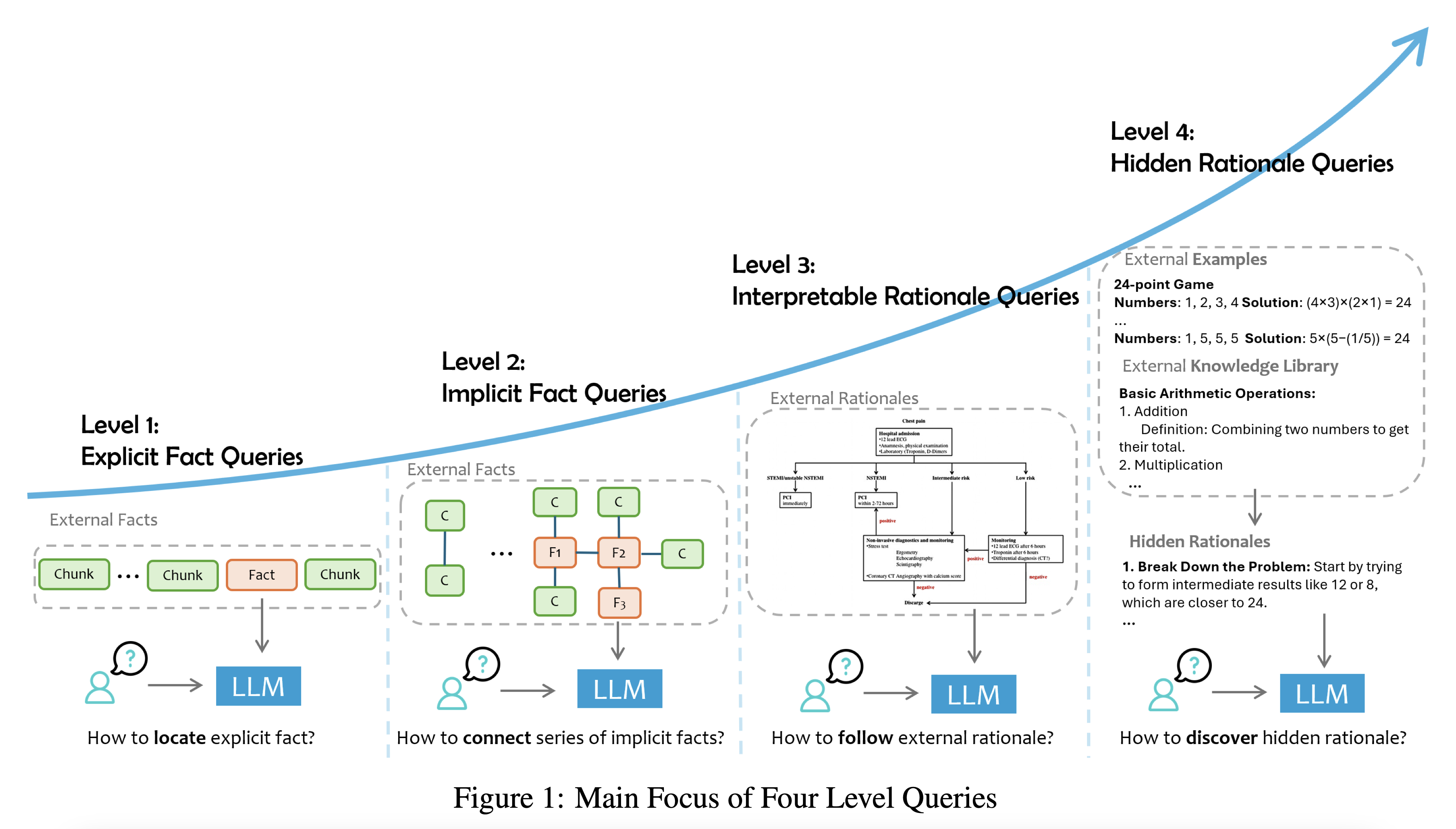
One of the key contributions of the research is a novel categorization of queries based on their complexity and reliance on external data. This stratification helps in understanding the varying levels of cognitive processing required by LLMs to generate accurate and relevant responses. The paper introduces four distinct levels of queries, each presenting unique challenges and requiring tailored solutions.
 |
|---|
| https://arxiv.org/abs/2409.14924 |
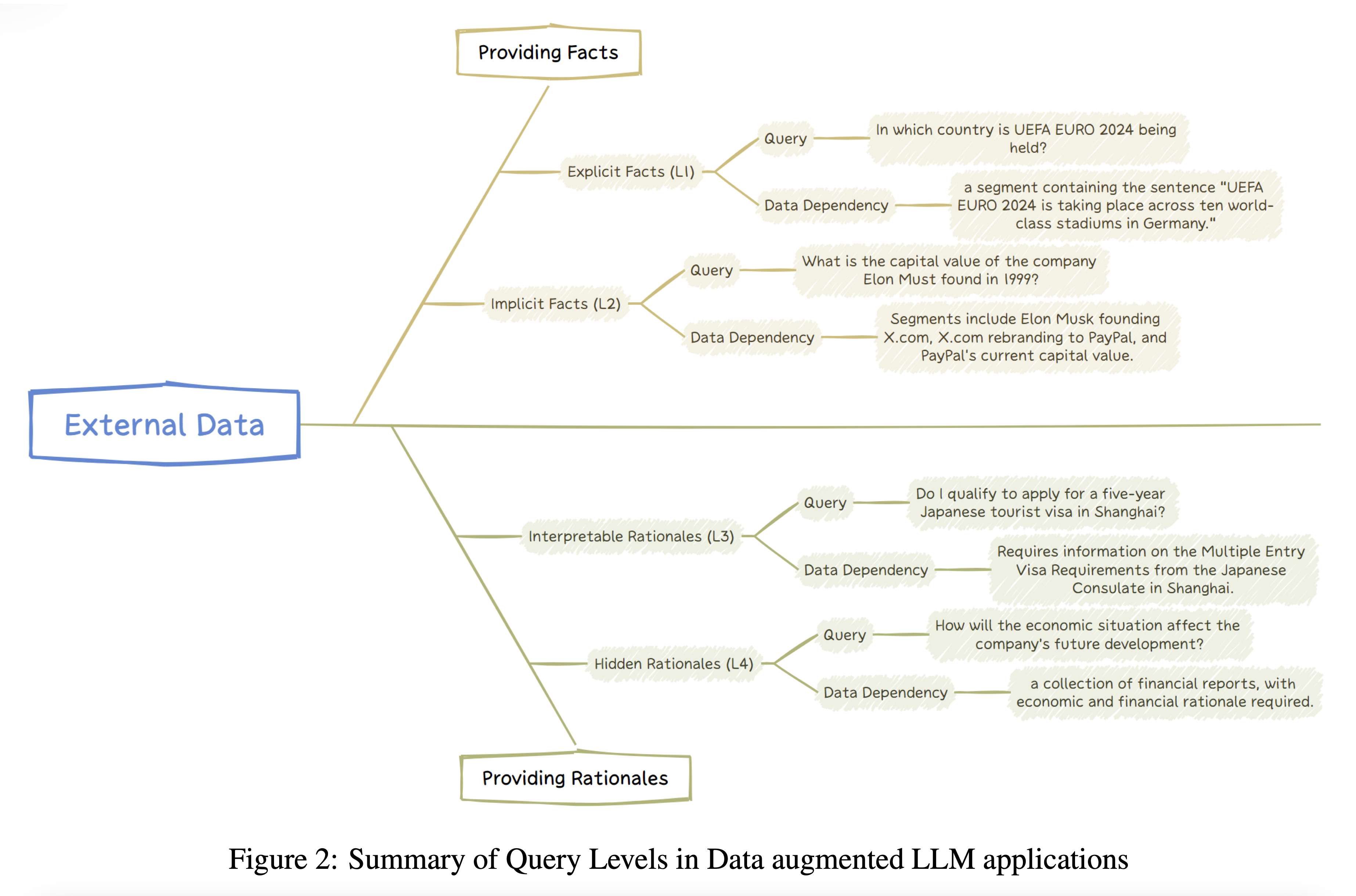
The first level, termed “Explicit Fact Queries” (Q1), represents the simplest type of queries. “These queries are asking about explicit facts directly present in the given data without requiring any additional reasoning.” (Stratification of Queries) For example, asking about the location of the 2024 Summer Olympics would fall into this category. The system’s primary task is to locate and extract the relevant information from the data. Formally, the paper defines these queries as follows: “For any query q and its corresponding answer a, an explicit fact query is one where there exists: A retrieval component rD : Q → P(D) that identifies the relevant data segments from D necessary to answer q. A response generator θ, typically a prompted LLM inference, that constructs the answer a based solely on the information retrieved by rD.” (Explicit Fact Queries (L1))
Moving up in complexity, we encounter “Implicit Fact Queries” (Q2). These queries require synthesizing information from multiple sources or making simple inferences. The paper describes them as “asking about implicit facts in the data, which are not immediately obvious and may require some level of common sense reasoning or basic logical deductions.” (Stratification of Queries) An example would be asking about the majority party in the country where Canberra is located, which requires combining the facts that Canberra is in Australia and identifying the current majority party in Australia. The formal definition provided in the paper states that “For any query q and its corresponding answer a, a Q2 fact query is one where: There exists a set of explicit fact queries {q1, q2, …, qm} ⊂ Q1, each of which can be directly retrieved from specific data segments within the dataset D…“ (Implicit Fact Queries (L2))
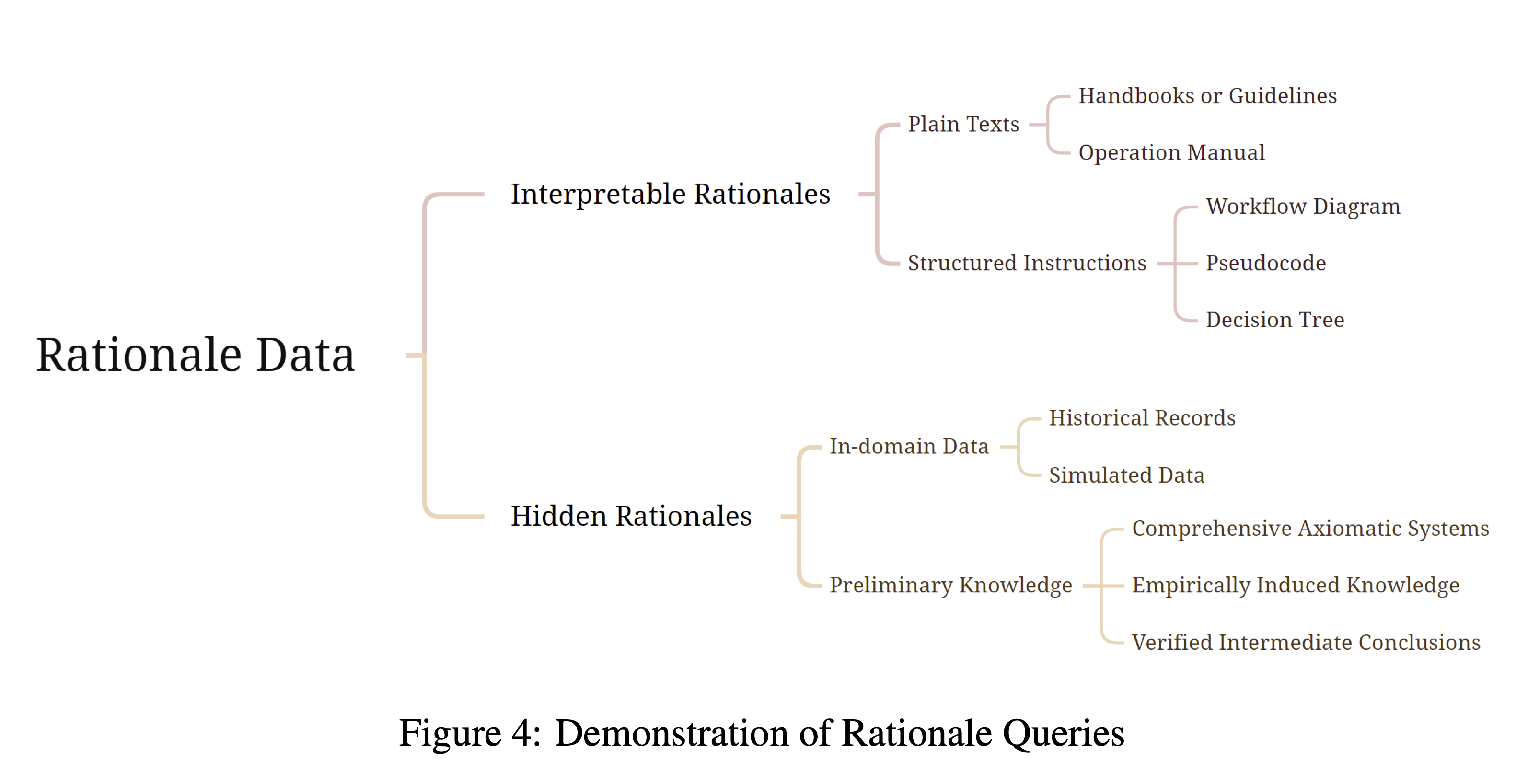
The third level introduces “Interpretable Rationale Queries” (L3), which demand understanding and applying domain-specific reasoning or guidelines that are explicitly provided in the external data. The paper explains that these queries “demand not only a grasp of the factual content but also the capacity to comprehend and apply domain-specific rationales that are integral to the data’s context.” (Stratification of Queries) An example would be diagnosing a patient with specific symptoms based on a medical guideline. These queries often involve interpreting and following structured instructions, workflows, or decision trees.
The most challenging category is “Hidden Rationale Queries” (L4). Here, the reasoning process is not explicitly stated but must be inferred from patterns in the data. The paper describes these as queries where “the rationales are not explicitly documented but must be inferred from patterns and outcomes observed in external data.” (Stratification of Queries) An example would be predicting how economic situations might affect a company’s future development based on financial reports. This level requires the LLM to “analyze and extract hidden patterns, principles, or strategies from the data to answer the query.” (Hidden Rationale Queries (L4))
 |
|---|
| https://arxiv.org/abs/2409.14924 |
To address these varying levels of query complexity, researchers have developed a range of techniques, with Retrieval-Augmented Generation (RAG) emerging as a particularly effective approach for handling Level-1 and Level-2 queries. The RAG process typically involves three main components: data processing, data retrieval, and response generation.
In the data processing phase, the system must handle multi-modal documents, extracting information from text, tables, and figures coherently. A key challenge here is chunking optimization - segmenting long documents into manageable pieces while preserving context. The paper highlights various chunking strategies, noting that “Larger text chunks can preserve more of the semantic coherence of the context, but they also tend to contain more noise within each chunk.” (Data Processing Enhancement)
The data retrieval phase involves indexing the processed data for efficient search, aligning queries with relevant document segments, and re-ranking and filtering retrieved information. The paper discusses several advanced techniques in this area, including dense retrieval methods like LLM2vec and Llama2Vec. For instance, “LLM2vec modifies the attention mechanism of a pre-trained LLM to a bidirectional one and employs the masked next-token prediction method for unsupervised training, resulting in an LLM-based dense retrieval embedder.” (Data Retrieval Enhancement)
 |
|---|
| https://arxiv.org/abs/2409.14924 |
In the response generation phase, the system must integrate the retrieved information with the LLM’s knowledge, handle potential conflicts, and generate coherent and accurate responses. The paper highlights techniques for enhancing this process, noting that “Supervised fine-tuning is an effective method to enhance the generation performance in RAG systems.” (Response Generation Enhancement)
For higher-level queries, more advanced techniques are required. The paper discusses several approaches for handling Implicit Fact Queries (Level-2), including iterative RAG methods like ReAct and Self-RAG, which perform multiple rounds of retrieval and generation to progressively refine answers. For Interpretable Rationale Queries (Level-3), techniques like prompt tuning and Chain of Thought prompting are explored. The paper describes how these methods can guide the LLM through step-by-step reasoning processes, improving transparency and accuracy.
Hidden Rationale Queries (Level-4) present the most significant challenges. The paper discusses several approaches to address these, including offline learning methods like STaR and LEAP, which extract rules and patterns from data before query time. In-context learning techniques are also explored, with methods like DIN-SQL demonstrating how complex problems can be decomposed into simpler subtasks. Fine-tuning approaches are also discussed, with examples like ChatTimeLlama for temporal reasoning and MAmmoTH for mathematical problem-solving.
The research identifies several key challenges in developing effective data-augmented LLM applications. One significant issue is logical retrieval, particularly for hidden rationale queries. The paper notes that “For questions involving hidden rationales, the helpfulness of external data does not simply depend on entity-level or semantic similarity, but rather on logical congruence or thematic alignment.” (Challenges and Solutions) This necessitates the development of more sophisticated retrieval algorithms that can parse and identify underlying logical structures.
 |
|---|
| https://arxiv.org/abs/2409.14924 |
Another crucial challenge is data insufficiency, especially in scenarios where relevant information is dispersed across multiple sources or presented through examples rather than explicit statements. The paper explains that “Fundamentally, external data may not explicitly contain the guidance or answers relevant to the current query. Instead, relevant information is often embedded in dispersed knowledges or illustrated through examples.” (Challenges and Solutions)
Looking to the future, the paper outlines several promising research directions. These include improving retrieval algorithms for more complex queries, especially those requiring multi-hop reasoning or hidden rationale understanding. Enhancing the interpretability of data-augmented systems is another key area, aiming to provide more transparent decision-making processes. The development of more efficient methods for integrating external knowledge into LLMs is also highlighted as a crucial direction for future work.
 |
|---|
| https://arxiv.org/abs/2409.14924 |
In conclusion, data-augmented Large Language Models represent a significant advancement in natural language processing, offering improved accuracy, relevance, and reliability across a wide range of applications. The research paper “RAG and Beyond” provides a comprehensive framework for understanding and developing these systems, from query categorization to advanced techniques for handling complex reasoning tasks. As the field continues to evolve, we can expect to see even more sophisticated and capable data-augmented LLMs that push the boundaries of what’s possible in natural language understanding and generation. By addressing the challenges identified in the research and exploring new techniques for integrating external knowledge, researchers and developers can create AI systems that combine the strengths of LLMs with the richness and specificity of external data sources, unlocking new possibilities in artificial intelligence and natural language processing.