RAG Foundry: A Framework for Enhancing LLMs for RAG

In recent years, the field of artificial intelligence has gone through a lot of advancements, particularly in the domain of Large Language Models (LLMs). These models have shown capabilities in various natural language processing tasks, changing how we interact with and utilize AI systems. Despite these abilities, LLMs face challenges and limitations in accuracy, latest information access, and context handling.
To address these challenges, researchers have been exploring Retrieval-Augmented Generation (RAG), a method that enhances LLMs by integrating external information retrieval mechanisms. While RAG shows great potential, the development and evaluation of RAG systems present their own set of complexities. In this context a team of researchers at Intel has introduced RAG Foundry, an open-source framework designed to simplify and streamline the process of creating, training, and evaluating RAG-enhanced language models. In this article, we will learn more about the research paper “RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation” by Fleischer et al. (2024). We will explore the background of the study, the research objectives and hypotheses, the methodology employed, the results and findings, and the limitations and future work identified by the researchers.
So, let’s begin.
 |
|---|
| From RAG Foundry |
Background of the research
As mentioned above, the field of artificial intelligence has been transformed by Large Language Models (LLMs), which have demonstrated strong capabilities across various tasks. However, these models have their limitations. As noted in the paper “Large Language Models (LLMs) have emerged as a transformative force in the field of AI, demonstrating an impressive ability to perform a wide range of tasks that traditionally required human intelligence. Despite their impressive capabilities, LLMs have inherent limitations. These models can produce plausible-sounding but incorrect or nonsensical answers, struggle with factual accuracy, lack access to up-to-date information after their training cutoff and struggle in attending to relevant information in large contexts” [Introduction]
To address these limitations, researchers have been exploring Retrieval-Augmented Generation (RAG). The paper explains “Retrieval-Augmented Generation (RAG) enhances LLMs performance by integrating external information using retrieval mechanisms. Combining retrieval that leverages vast knowledge-bases outside the knowledge of the model, effectively addresses knowledge limitations, can reduce hallucinations, improve the relevance of generated content, provide interpretability and could be vastly more cost-efficient” [Introduction]
However, implementing and evaluating RAG systems presents significant challenges “The implementation of RAG systems is inherently complex and requires a series of intricate decisions that can significantly impact the performance of the system. This process demands a thorough understanding of the data and use case, and often, solutions do not generalize well to other domains.” [Introduction]
Furthermore “Evaluating RAG systems presents a challenge due to the dual reliance on retrieval accuracy and generative quality. These systems require a sophisticated evaluation suite that accounts for the interplay among the retrieved information, the formalization of data, and the generated output” [Introduction]
Research Objectives and Hypotheses
In response to these challenges, the researchers developed RAG Foundry. The paper states “We introduce RAG FOUNDRY, an open-source framework for augmenting large language models for RAG use cases. RAG FOUNDRY integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings.”[Abstract]
The primary objective of this research was to create a framework that simplifies RAG system development and evaluation. The researchers hypothesized that “This integration enables rapid prototyping and experimentation with various RAG techniques, allowing users to easily generate datasets and train RAG models using internal or specialized knowledge sources.” [Abstract]
Methodology
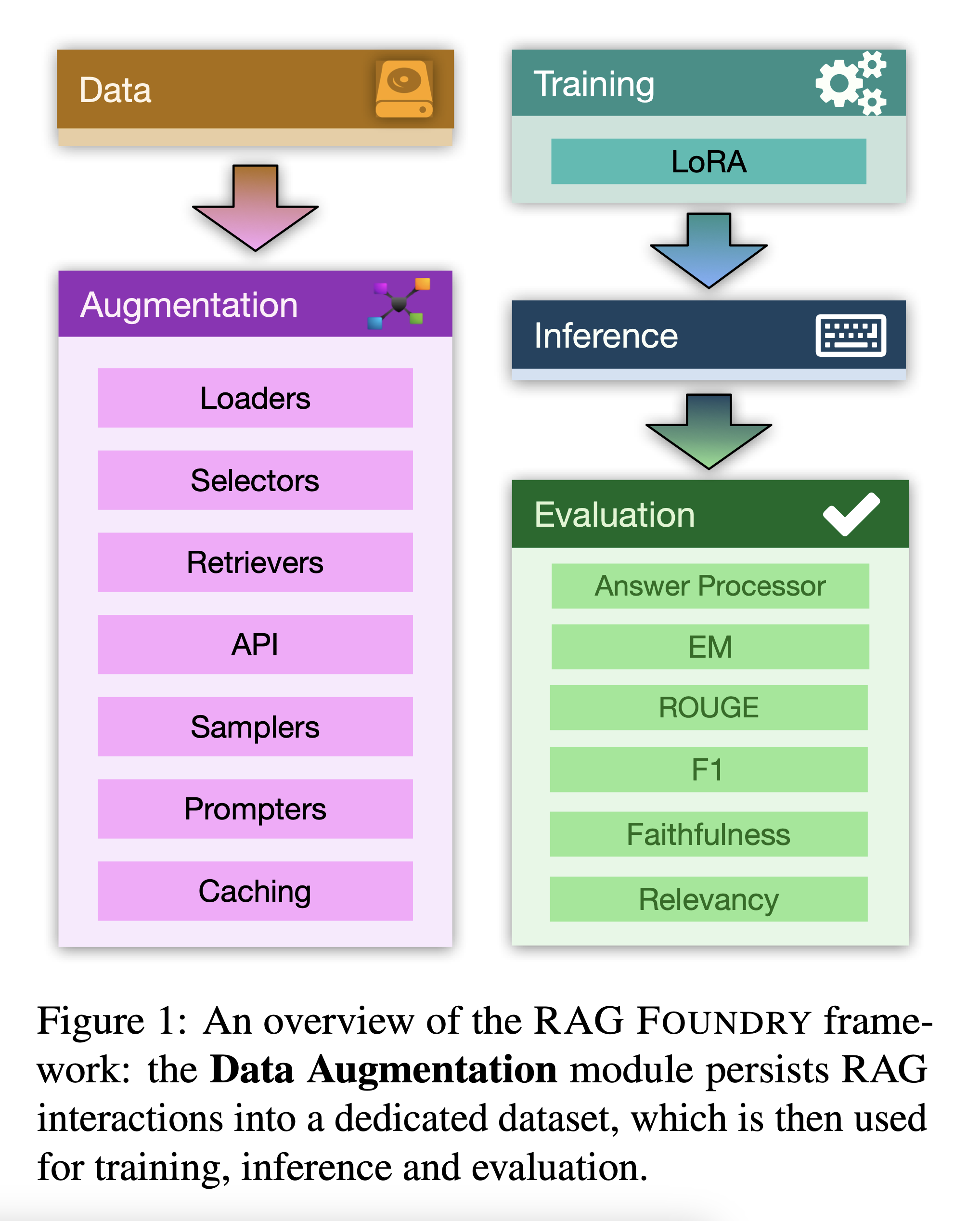
The methodology employed in this study involved the design and implementation of the RAG Foundry framework. The framework consists of four main modules,
- Data Creation and Processing
- Training
- Inference
- Evaluation
Data Creation and Processing Module
This module is particularly sophisticated “The processing module facilitates the creation of context-enhanced datasets by persisting RAG interactions, which are essential for RAG-oriented training and inference. These interactions encompass dataset loading, column normalization, data aggregation, information retrieval, template-based prompt creation, and various other forms of pre-processing.” [Data Creation and Processing]
The module is highly flexible “The processing module is comprised of an abstract pipeline with multiple steps, each defined by Python classes that implement specific data processing functionalities. These steps are categorized into two types:
- Global Steps: Can act on the dataset as a whole, making them useful for operations such as aggregations, group-by, examples filtering, join operations, and more.
- Local Steps: Operate on individual examples, making them suitable for tasks such as retrieval, text processing, and field manipulation.”[Data Creation and Processing]
 |
|---|
| From RAG Foundry |
Training Module
The training module leverages established frameworks, “We provide a training module to fine-tune models given the datasets created by the previous processing module. The training module relies on the well established training framework TRL and supports advanced and efficient training techniques, e.g. LoRA” [Training]
 |
|---|
| From RAG Foundry |
Inference Module
The inference module is designed for efficiency, “The inference module generates predictions given the processed datasets created by the processing module. Inference is conceptually separated from the evaluation step, since it is more computationally demanding than evaluation. Additionally, one can run multiple evaluations on a single, prepared inference results file.” [Inference]
 |
|---|
| From RAG Foundry |
Evaluation Module
The evaluation module is comprehensive, “The evaluation module allows users to run collections of metrics to evaluate RAG techniques and tuning processes. The evaluation module loads the output of the inference module and runs a configurable list of metrics. Metrics are classes implemented in the library. These classes can be as simple as wrappers around other evaluation libraries, or can be implemented by the user.” [Evaluation]
 |
|---|
| From RAG Foundry |
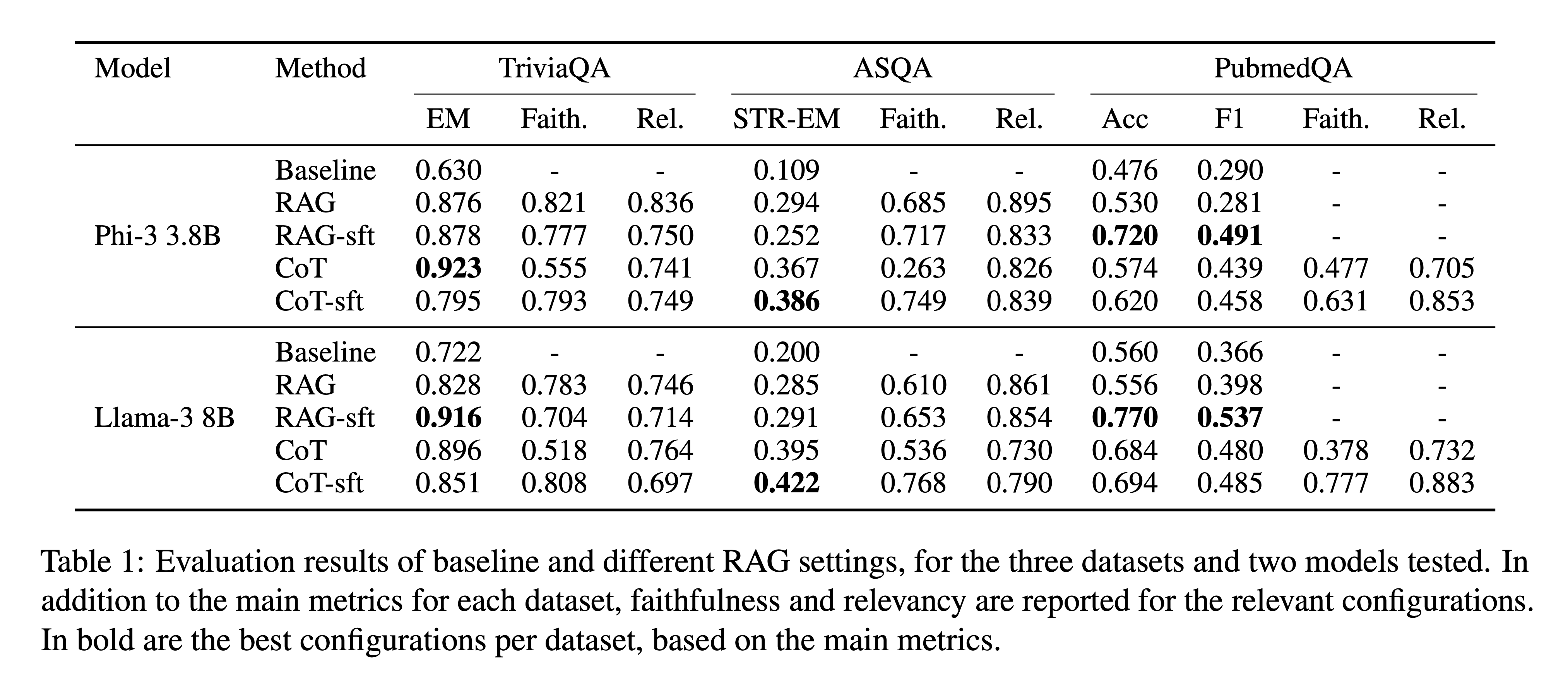
To demonstrate the effectiveness of RAG Foundry, the researchers conducted experiments using two representative models: Llama-3 and Phi-3. They tested these models on three knowledge-intensive question-answering datasets: TriviaQA, ASQA, and PubmedQA. The researchers explored several RAG augmentation techniques, “We explore several techniques for RAG augmentation, and use RAG FOUNDRY to easily implement and evaluate their benefit. As an initial step, we evaluate unmodified models; we set Baseline as a configuration that is defined by running unmodified models and without any external knowledge. We define a RAG setting that introduces top-relevant documents in a consistent prompt template format with a system instruction, and a CoT scheme which guides the model to use the retrieved context, explain the steps, quote relevant parts and produce a final answer. Complementing that, we explore fine-tuning recipes.” [RAG Augmentation Techniques]
Results and Findings
The experiments conducted using RAG Foundry yielded several findings.
 |
|---|
| From RAG Foundry |
The TriviaQA dataset:
“For TriviaQA we observe the following: retrieved context improves the results, fine-tuning the RAG setting improves the results, fine-tuning on CoT reasoning (which includes training on a combination of gold passages and distractor passages) decreases performance. Best method is model dependent for this dataset.” [Results]
The ASQA dataset:
“For ASQA, we similarly observe every method improves upon the baseline, CoT reasoning produces consistent improvement in both models, as well as fine-tuning of the CoT configuration, which shows to perform best.”[Results]
The PubmedQA dataset:
“Finally, for PubmedQA, we observe that almost all methods improve upon the baseline (with one exception); CoT reasoning improves upon the untrained RAG setting, but upon fine-tuning, the RAG method appears to perform best in both models.” [Results]
The researchers also evaluated the faithfulness and relevancy of the generated responses:
“Inspecting the faithfulness and relevancy scores, notice that not all configurations are valid to be measured: these metrics require context, so are irrelevant for the baseline method. Additionally, in the PubmedQA dataset, the answers are binary Yes/No; only in the CoT configurations the LLMs produce a reasoning, which can be evaluated. Finally, the faithfulness and relevancy scores often do not correlate with the main metrics, neither with each other, possibly indicating they capture different aspects of the retrieval and generated results, and represent a trade-off in performance.” [Results]
Overall, the results demonstrated:
“The results demonstrate the usefulness of RAG techniques for improving performance, as well as the need to carefully evaluate different aspects of a RAG system, on a diverse set of datasets, as effort on developing generalized techniques is ongoing.” [Results]
Limitations and Future Work
Despite the promising results, the researchers acknowledge several limitations of their study, “Our hope is that the library will be useful to as many people and use-cases as possible. However, due to time and resource constraint, we were able to demonstrate its usefulness on a subset of tasks and datasets. Future work can expand the evaluation to other tasks, as well as implementing other RAG techniques and evaluations.” [Limitations and Future Plans]
The researchers also recognize potential challenges in adapting the framework to specific workflows, “Although we designed the library to be general and customizable, there might be specific workflows which will be difficult to run as-is and some code changes may be required. The library proved useful for our own research projects on a diverse set of datasets and tasks and extending it is easy and straightforward.” [Limitations and Future Plans]
Regarding documentation, the researchers added, “Finally, despite our best efforts to offer detailed documentation in the library, there could be some missing details regarding some functionality or specific use-cases. The code repository will accept suggestions, bug-fixes and pull requests.” [Limitations and Future Plans]
Looking to the future, the researchers suggest several directions for further research and development, including expanding the evaluation to other NLP tasks, enhancing the framework’s flexibility, improving documentation, addressing scalability issues, and incorporating user-centric evaluation metrics and ethical considerations.
In conclusion, while RAG Foundry represents a significant advancement in the field of Retrieval-Augmented Generation(RAG) for Large Language Models, there is still ample room for improvement and expansion. The open-source nature of the framework invites collaboration and continuous refinement, leading the way for future innovations in this rapidly evolving field of AI research.