Model Collapse in AI

In recent years, artificial intelligence (AI) has become an integral part of our daily lives, assisting us with tasks ranging from writing emails to creating artwork. However, as AI systems become more easy to use and generate more content, researchers have identified a concerning issue called “model collapse.” This issue could potentially impact the quality and fairness of AI-generated content in the future.
Regarding this topic, let’s understand the below two research papers:
AI models collapse when trained on recursively generated data
AI produces gibberish when trained on too much AI-generated data
Model collapse is a complex concept, but it’s crucial to understand its implications. Shumailov et al. provide a clear definition in their groundbreaking research. They describe it as “a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation” (p. 755). In simpler terms, when AI systems learn too much from their own creations rather than from human-generated content, they can start to produce less diverse and less accurate outputs over time.
The process of model collapse occurs in stages. Initially, an AI model is trained on real data from the internet. This model then creates new content, which is subsequently added back to the internet. When a new AI model is trained, some of its training data now includes this AI-created content. As this cycle repeats, each new AI model learns more from AI-created content and less from human-created content. This feedback loop can lead to a gradual degradation in the quality and diversity of AI-generated content.
Research Objectives and Hypotheses
The primary objective of the research conducted by Shumailov et al. was to investigate the phenomenon of model collapse in AI systems, particularly in large language models (LLMs). The researchers aimed to understand the mechanisms behind model collapse, its effects on AI-generated content, and its potential long-term implications for AI development.
The main hypothesis of the study was that the indiscriminate use of AI-generated content in training subsequent AI models would lead to a degradation in model performance and a loss of diversity in outputs. Specifically, the researchers hypothesized that this process would cause AI models to forget rare or uncommon information, leading to a narrowing of their knowledge base and creative output.
Methodology
To study model collapse in depth, Shumailov et al. used a concept of combining theoretical analysis and practical experiments:
Theoretical Analysis: The researchers created mathematical models to understand how errors accumulate over time in AI systems. They identified three main types of errors contributing to model collapse named, statistical approximation error, functional expressivity error, and functional approximation error. As Shumailov et al. explain, statistical approximation error “arises owing to the number of samples being finite, and disappears as the number of samples tends to infinity” (p. 755). Functional expressivity error occurs from the limitations of AI models in representing complex real-world information, “owing to limited function approximator expressiveness” (p. 756). Functional approximation error occurs from imperfections in the AI training process, “primarily from the limitations of learning procedures, for example, structural bias of stochastic gradient descent or choice of objective” (p. 756).
Practical Experiments: The researchers conducted experiments with language models, training them on data generated by other AI models and observing the changes over several “generations” of models. They used the OPT-125m causal language model and fine-tuned it on the wikitext2 dataset (p. 758). For data generation, they used a five-way beam search and created artificial datasets of the same size as the original training set.
Results and Findings
The research generated several significant findings:
Loss of Rare Information: One of the key issues that arise during model collapse is the loss of rare or uncommon information. As Shumailov et al. explain, “over time, models start losing information about the true distribution, which first starts with tails disappearing” (p. 755). This means that AI systems might begin to forget about less common words, ideas, or facts, leading to a narrowing of their knowledge base and creative output.
Increased Repetition: The researchers observed that “data generated by language models in our experiments end up containing a large number of repeating phrases” (p. 758). This repetition can make AI-generated content less engaging and less useful for human readers or users.
Simplification of Outputs: As model collapse progresses, AI outputs going to become simpler and less varied. The researchers observed that “over the generations, models tend to produce more probable sequences from the original data and start introducing their own improbable sequences, that is, errors” (p. 758).
Performance Degradation: The results showed that “training with generated data allows us to adapt to the underlying task, losing some performance” (p. 758), indicating that while AI models can learn from AI-generated data, there’s a gradual degradation in their performance.
Meaningless Outputs: In extreme cases of model collapse, AI systems might even start producing nonsense outputs. The researchers provided an example where an AI model, when asked about church architecture, ended up discussing “black-tailed jackrabbits, white-tailed jackrabbits, blue-tailed jackrabbits, red-tailed jackrabbits, yellow-“ (p. 758).
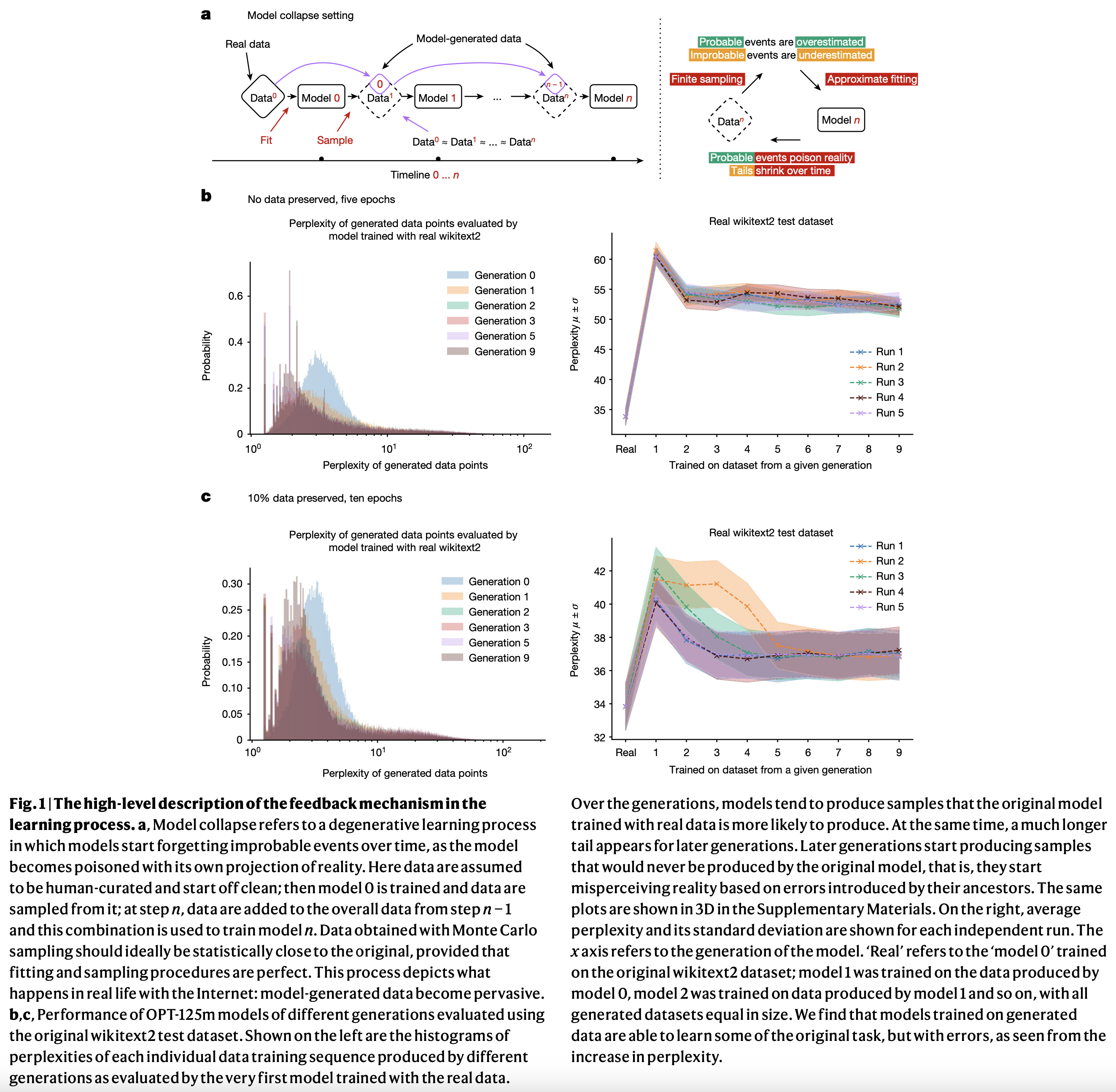 |
|---|
| From AI models collapse when trained on recursively generated data |
Discussions
The results of this study have significant implications for the future of AI development and deployment. The observed effects of model collapse raise concerns about the long-term reliability and usefulness of AI systems, especially as they become more integrated into various aspects of our lives.
The loss of rare information and the tendency towards simplification and repetition in AI outputs could lead to a degradation of AI-generated content. As Emily Wenger et al. points out, “Collapsed models overlook less-common elements from their training data, and so fail to reflect the complexity and nuance of the world” (p. 742). This could result in AI systems that produce biased content, potentially degrading existing imbalance in digital spaces.
The degradation in model performance over generations of training on AI-generated data suggests that there might be a “first mover advantage” in AI development. As Wenger et al. mentioned and acknowledged the work of Shumailov et al., “The companies that sourced training data from the pre-AI Internet might have models that better represent the real world” (p. 743). This raises important questions about the future of AI development and the potential for monopoly in the AI industry.
The studies also highlights the role of data quality in AI development. As AI-generated content becomes more available online, distinguishing between human-created and AI-created content becomes increasingly important. The researchers emphasize that “data about human interactions with LLMs will be increasingly valuable” (p. 755), suggests that preserving and prioritizing human-generated content will be essential for the continued development of effective and reliable AI systems.
Overall, these researches makes several significant contributions to the field of AI:
- It provides a clear definition and explanation of model collapse, a concept that had not been extensively studied before. As Shumailov et al. state, “Model collapse is a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation” (p. 755).
- It provides a theoretical framework for understanding the mechanisms behind model collapse, identifying specific types of errors that contribute to this process. The researchers explain that these errors include “Statistical approximation error… Functional expressivity error… [and] Functional approximation error” (p. 755-756).
- The study presents evidence of model collapse in language models, demonstrating its effects on AI-generated content over multiple generations of training. The authors mentioned that “over the generations, models tend to produce more probable sequences from the original data and start introducing their own improbable sequences, that is, errors” (p. 758).
- It raises questions about the long-term sustainability of current AI training practices and the potential need for new approaches to preserve the quality and diversity of AI outputs. As the researchers highlighted, “to sustain learning over a long period of time, we need to make sure that access to the original data source is preserved” (p. 759).
- The research highlights the importance of maintaining access to high-quality, human-generated data for AI training, even as AI-generated content becomes more prevalent. Shumailov et al. argue that “data about human interactions with LLMs will be increasingly valuable” (p. 755).
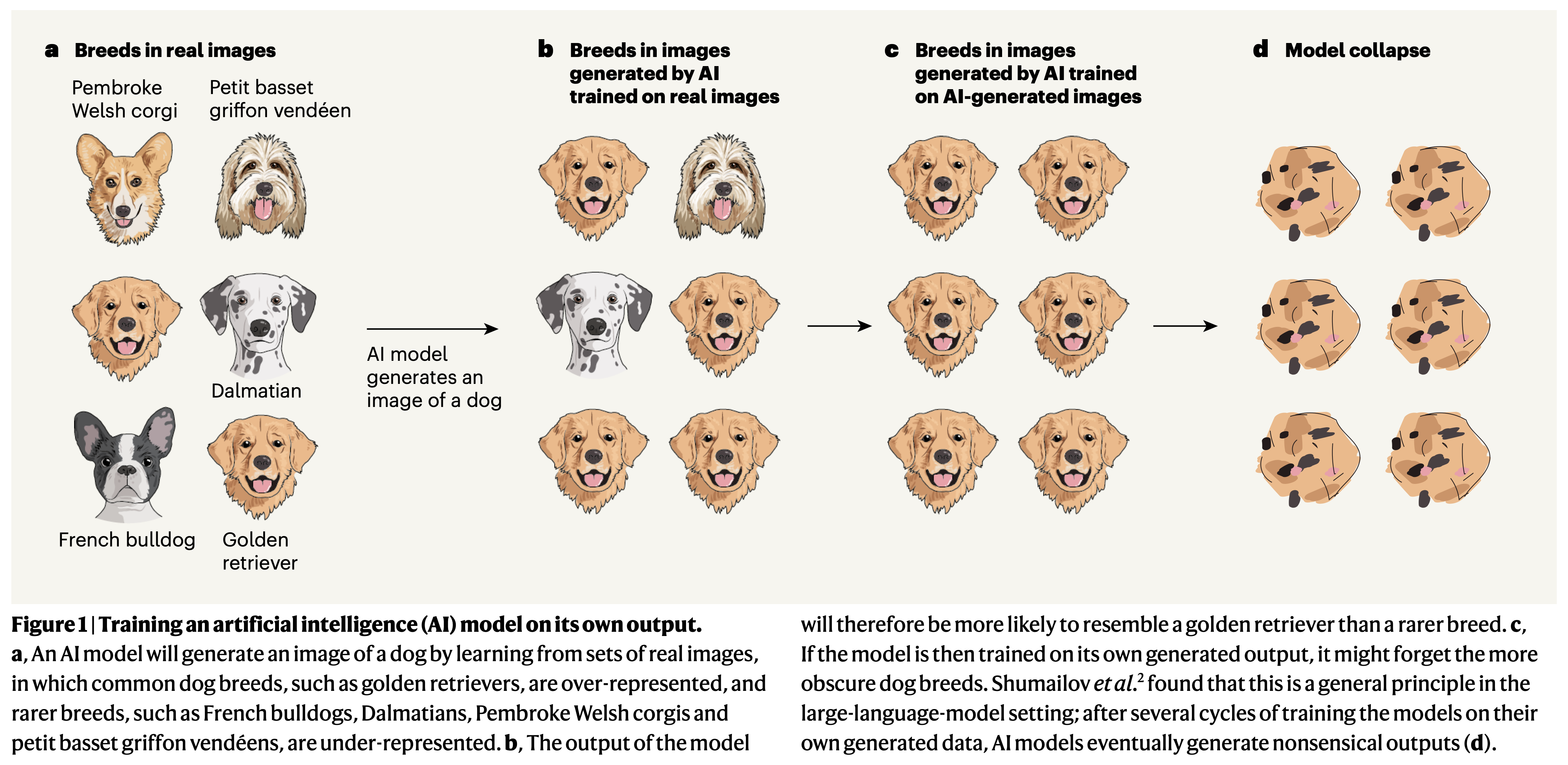 |
|---|
| From AI produces gibberish when trained on too much AI-generated data |
Achievements
The significance of this research lies in its potential to shape the future direction of AI development. By identifying the concept of model collapse, both the studies provide a foundation for addressing this challenge and ensuring the long-term viability of AI systems.
The research achieves several important goals:
- It brings attention to an issue that could affect the quality and fairness of AI-generated content in the future. As Wenger et al. mentioned, “Collapsed models overlook less-common elements from their training data, and so fail to reflect the complexity and nuance of the world” (p. 743).
- It provides a theoretical and experimental basis for understanding model collapse, which can help future research and development efforts in AI. The researchers demonstrate this through their experiments, showing that “training with generated data allows us to adapt to the underlying task, losing some performance” (p. 758).
- The study highlighted the importance of diversity and representation in AI training data and outputs, contributing to ongoing discussions about AI ethics and fairness. Shumailov et al. highlighted that “low-probability events are often relevant to marginalized groups” and are “also vital to understand complex systems” (p. 759).
Limitations and Future Work
While this study provides valuable insights into model collapse, there are several limitations and areas for future research:
- The research primarily focused on language models. As Shumailov et al. acknowledge, “We can easily replicate all experiments covered in this paper with larger language models in non-fine-tuning settings to demonstrate model collapse” (p. 757). Future studies could explore how model collapse affects other types of AI systems, such as those used for image or video generation.
- The experiments were conducted over a limited number of generations. The researchers note that “in all experiments, generational learning is only performed on a finite (usually small) number of generations” (p. 758). Longer-term studies could provide more insights into the progression of model collapse over extended periods.
- While the researchers suggested some potential solutions, such as watermarking AI-generated content, these solutions have not been extensively tested. As Wenger points out, “watermarks can be easily removed from AI-generated images” (p. 743), indicating that more work is needed to develop and evaluate effective strategies for mitigating model collapse.
- The ethical implications of model collapse justify further investigation. Shumailov et al. highlight this concern, stating that “Preserving the ability of LLMs to model low-probability events is essential to the fairness of their predictions: such events are often relevant to marginalized groups” (p. 759). Future research could dive deeper into these considerations and propose frameworks for developing AI systems that are resistant to model collapse.
- The study primarily considered scenarios where AI models are trained on their own outputs. As the researchers note, “Whether a model collapses when trained on other models’ output remains to be seen” (p. 743). Future research could explore more complex scenarios involving multiple AI models or hybrid human-AI content generation.
In conclusion, while this research represents a significant step forward in understanding model collapse, it also opens up many new options for investigation. As Shumailov et al. mentioned, “It is now clear that generative artificial intelligence (AI) such as large language models (LLMs) is here to stay and will substantially change the ecosystem of online text and images” (p. 755). Addressing the challenges occurred by model collapse will be crucial for ensuring the development of robust and reliable AI systems in this continuously changing tech environment.