HI-SQL: Optimizing Text-to-SQL Systems through Dynamic Hint Integration

Text-to-SQL generation represents a critical advancement in database accessibility, enabling users to query databases using natural language instead of requiring specialized SQL knowledge. However, current systems face significant challenges when handling complex queries involving multi-table joins, nested conditions, and intricate database operations. The task of converting natural language queries into SQL statements, known as Text-to-SQL parsing, has consistently been a major area of interest within both the natural language processing and database communities [Section I]. The HI-SQL system addresses these limitations through an innovative approach that leverages historical query logs to generate contextual hints, fundamentally improving query accuracy while reducing computational overhead.
This technology enables users to interact with databases without requiring proficiency in SQL, thereby democratizing data access and facilitating informed decision-making across various domains [Section I]. Modern database environments frequently contain hundreds of tables with complex relationships, making accurate SQL generation increasingly difficult for automated systems.
The complexity of enterprise databases presents substantial challenges for automated query generation. Current advancements in large language models (LLMs) have further propelled the field, enhancing the understanding of natural language semantics and the generation of accurate SQL queries [Section I]. Real-world databases often contain over 1,000 columns and intricate foreign key relationships that must be properly understood and utilized. These systems require sophisticated understanding of both database schema structure and the semantic relationships between different data entities.
Understanding Text-to-SQL Systems
The Evolution of Database Query Generation
Text-to-SQL systems have evolved significantly from early rule-based approaches to modern neural network implementations. The advent of deep learning and neural network models marked a significant shift, introducing sequence-to-sequence architectures that improved the translation of natural language to SQL [Section I]. Traditional systems relied heavily on manually crafted rules and human-engineered features, which provided limited scalability and adaptability across diverse database schemas.
Early Text-to-SQL systems relied heavily on rule-based methods and human-engineered features, which, while effective to a degree, often struggled with scalability and adaptability to diverse database schemas [Section I]. These traditional approaches could not adequately handle the complexity of modern enterprise databases with their intricate relationships and domain-specific terminology.
The transition from rule-based systems to neural approaches represented a significant advancement in query generation capabilities. Recent studies have highlighted the impact of LLMs on Text-to-SQL parsing, noting their ability to capture complex linguistic patterns and improve performance across benchmarks [Section I]. Recurrent Neural Networks and Long Short-Term Memory networks enabled better encoding of user queries and database schemas, utilizing slot-filling and auto-regressive decoding techniques to construct SQL queries. These developments laid the foundation for more sophisticated approaches using transformer architectures.
Current Challenges in Complex Query Generation
Modern Text-to-SQL systems face substantial challenges when processing queries that require understanding of multi-table relationships and complex logical operations. Despite significant advancements, generating accurate SQL queries for complex operations that span multiple tables, nested conditions, and intricate joins continues to be a challenge within Text-to-SQL systems [Section I]. These challenges become particularly pronounced in enterprise environments where databases contain hundreds of interconnected tables.
The complexity of real-world database schemas creates several specific challenges for automated query generation systems. The development of large-scale human-labeled data sets, such as Spider and BIRD, has been instrumental in evaluating and advancing Text-to-SQL systems. These datasets provide diverse and complex queries that test the robustness and adaptability of current models [Section I]. Database schemas in enterprise environments often feature non-intuitive naming conventions, abbreviated column names, and complex foreign key relationships that require deep semantic understanding. Additionally, the sheer scale of enterprise databases, with their thousands of columns and hundreds of tables, creates computational challenges for systems attempting to process complete schema information.
Contemporary large language models have demonstrated remarkable capabilities in understanding programming code and generating SQL statements based on natural language prompts. However, these systems struggle with complex database operations involving multiple tables, advanced filtering conditions, and sophisticated SQL features. Unlike traditional agentic systems, such as CHASE-SQL, which often require labor-intensive human annotations or expert-crafted few-shot examples to design effective prompts, our approach automates the hint generation process [Section I]. The challenge extends beyond simple syntax generation to include proper understanding of database semantics and business logic embedded within schema relationships.
The Multi-Step Pipeline Problem
Recent efforts have focused on leveraging LLMs to address these issues by designing agentic systems that combine multi-step processes with verification methods for generating SQL queries. While these approaches have demonstrated effectiveness in improving query accuracy, they also lead to increased computational overhead due to the necessity of chaining multiple LLM calls [Section I]. These multi-step approaches create several fundamental problems that limit their practical deployment.
The computational overhead of multi-step systems comes from the need to execute multiple large language model calls in sequence, each requiring significant processing resources and time. This results in high token usage and latency, while also making the system vulnerable to error propagation, as inaccuracies in one stage can negatively impact subsequent steps, ultimately compromising the system’s reliability [Section I]. This error propagation represents a critical weakness in chain-based approaches.
Multi-step systems typically involve separate phases for schema linking, entity disambiguation, query generation, and verification. Each phase introduces potential failure points and increases the overall system complexity. By eliminating the need for human or domain-specific input in prompt design, our method significantly reduces manual effort and enhances scalability and adaptability across various database environments [Section I]. The computational cost scales linearly with the number of steps, making these approaches expensive for real-world deployment scenarios where thousands of queries may need processing daily.
The HI-SQL Innovation
Historical Query Analysis Approach
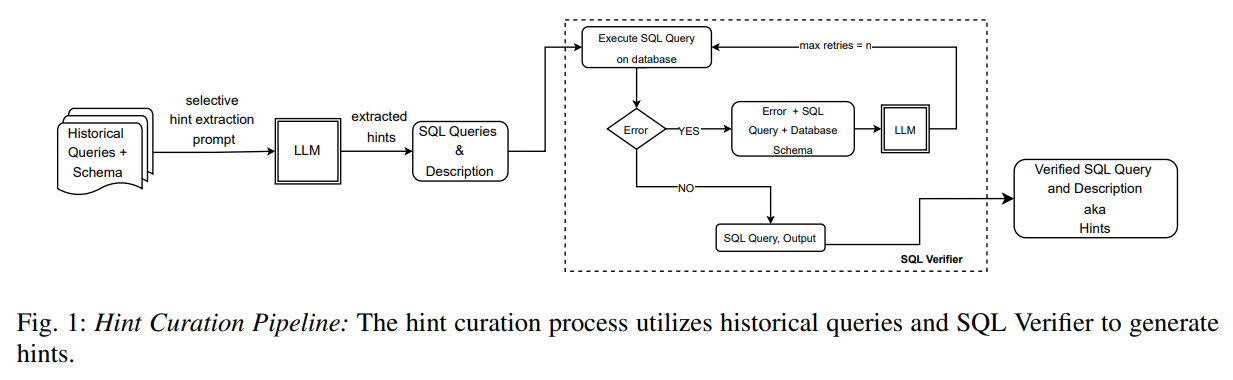
HI-SQL introduces a fundamentally different approach to Text-to-SQL generation by leveraging historical query patterns to create contextual hints that guide SQL generation. By systematically analyzing previously executed queries, our method generates contextual hints designed to address the complexities of handling multi-table queries, nested operations, and intricate conditions [Section I]. This approach represents a shift from multi-step processing to single-step generation enhanced by learned patterns.
The system’s approach to historical query analysis involves sophisticated pattern recognition and extraction techniques. These hints are seamlessly integrated into the SQL generation process, eliminating the need for costly multi-step approaches and reducing reliance on human-crafted prompts [Abstract]. Historical queries, along with their associated database schemas, are combined into structured prompts that guide the LLM in analyzing and identifying representative examples of complex query patterns [Section III.A]. This process ensures comprehensive coverage of diverse query structures and challenges commonly encountered in database systems.
The historical analysis process identifies critical patterns across multiple dimensions of query complexity. These prompts assist the LLM in extracting queries that showcase critical relationships between tables and address broader challenges in query design, including dynamic filtering, recursive structures, and integrating data from multiple sources [Section III.A]. The system recognizes patterns in table joins, including equi-joins, non-equi-joins, and self-joins, while understanding how grouping and sorting operations enhance query functionality. Additionally, the analysis captures advanced complexities such as hierarchical data structures, analytical computations, and set operations including unions, intersections, and differences.
Hint Generation Mechanism
The hint generation process represents the core innovation of the HI-SQL system. The Hint Curation process leverages a large language model (LLM) to select and refine a diverse set of historical queries that reflect varying levels of complexity. These queries encompass tasks such as managing relationships between multiple tables, employing advanced data linking methods, applying conditional filtering, and performing computational operations like aggregations and averages [Section III.A].
The selection process for historical queries follows sophisticated criteria designed to maximize learning potential. The extracted queries are run through the hosted database to verify their syntactical correctness. If any queries are found to be incorrect, the LLM automatically corrects them, thereby reducing reliance on manual review and correction [Section III.A]. The system identifies queries that demonstrate critical relationships between tables and address broader challenges in query design, including dynamic filtering, recursive structures, and data integration from multiple sources. This selective approach ensures that the generated hints provide maximum value for subsequent query generation tasks.
By relying on the LLM, this approach ensures a comprehensive exploration of diverse query structures and challenges commonly faced in database systems, minimizing the need for manual selection [Section III.A]. The automated nature of hint generation eliminates human bias and ensures consistent quality across different database domains and schema types.
Integration with SQL Generation Pipeline
The integration of generated hints into the SQL generation process represents a carefully designed architectural approach. For SQL generation, the LLM is provided with hints extracted through the Hint Curation process, along with the database schema and the Natural Language Query (NLQ), all formatted within a structured prompt [Section III.B]. This integration approach ensures that contextual information is available during the critical query generation phase.
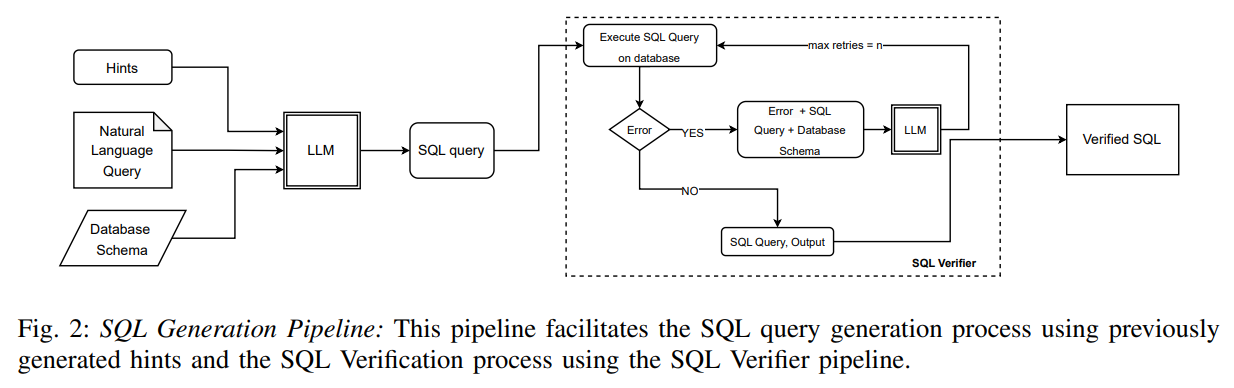
The system design incorporates modern large language model capabilities effectively. With the growing context window of modern LLMs, we do not utilise a query-specific schema filtering or linking module, thereby reducing the error incurred during schema linking [Section III.B]. This approach simplifies the architecture while taking advantage of increased model capacity to process complete schema information.
The structured prompt format ensures optimal utilization of the large language model’s capabilities. This enables the LLM to generate an SQL query corresponding to the NLQ. The generated SQL is then processed through an SQL verifier to ensure its correctness [Section III.B]. The prompt construction combines natural language queries, complete database schemas, and relevant hints in a format that maximizes the model’s understanding of query requirements and available database resources. This approach enables the model to generate accurate SQL queries without requiring multiple processing steps.
Technical Architecture Deep Dive
Hint Curation Component
The hint curation component represents the foundation of the HI-SQL system’s effectiveness. As mentioned earlier, The extracted queries are run through the hosted database to verify their syntactical correctness. If any queries are found to be incorrect, the LLM automatically corrects them, thereby reducing reliance on manual review and correction [Section III.A]. This verification process ensures that only valid, executable queries contribute to the hint generation process.
The curation process involves sophisticated analysis of query complexity patterns. In addition to handling multitable relationships and filtering, the LLM is tasked with recognizing more advanced complexities, such as hierarchical data structures, and analytical computations (e.g., row-based calculations), as well as set operations like unions, intersections, and differences [Section III.A]. This comprehensive analysis ensures that hints cover the full spectrum of SQL operations that may be required for complex query generation.
The system’s approach to hint selection prioritizes diversity and representativeness. It identifies key patterns in table joins for a database schema, such as equi-joins, non-equi-joins, and self-joins, while also understanding how grouping and sorting enhance query outputs [Section III.A]. The process identifies queries that showcase different types of table relationships, various filtering approaches, and multiple aggregation strategies. This diversity ensures that the hint collection provides comprehensive guidance for handling different types of query complexity that may be encountered during actual SQL generation tasks.
SQL Generation Architecture
The SQL generation component integrates seamlessly with the hint curation output to produce accurate queries. The final curated set of SQL queries, accompanied by detailed descriptions, provides actionable examples that improve the LLM’s ability to handle advanced query design [Section III.A]. The architecture processes natural language queries alongside database schemas and contextual hints to generate syntactically and semantically correct SQL statements. The system’s design emphasizes efficiency while maintaining high accuracy levels through intelligent use of contextual information.

The generation process leverages the full context window capabilities of modern large language models. Rather than attempting to filter or limit schema information, the system provides complete database structure information alongside relevant hints. By automating this hint-generation process, the need for human-driven tasks such as creating ontologies or crafting few-shot examples for multi-agent systems-is significantly reduced [Section III.A]. This approach ensures that the model has access to all necessary information for generating complex queries involving multiple tables and sophisticated operations.
The prompt engineering approach used in SQL generation carefully structures information to maximize model comprehension. This ensures a faster and more scalable approach to enhancing the LLM’s understanding of the complexities in query construction while also improving performance [Section III.A]. Natural language queries are presented alongside complete schema information and relevant historical patterns, creating a comprehensive context that enables accurate query generation. The structured format helps the model understand both the specific requirements of the current query and the general patterns that apply to the database domain.
SQL Verification System
The SQL verification component ensures the correctness and executability of generated queries. The SQL verification pipeline ensures the correctness of the generated SQL by executing it on a hosted database and checking for both results and errors. If errors are encountered, the error message, along with the schema and the NLQ, is fed back into the LLM to generate a corrected SQL query [Section III.C]. This verification approach provides immediate feedback on query correctness.
The verification system incorporates robust error handling and retry mechanisms. To address the non-deterministic and hallucinatory tendencies of LLMs, a retry loop has been implemented. If the LLM fails to correct the query, the verification process is retried up to a maximum of C attempts [Section III.C]. This approach ensures that temporary generation errors do not result in system failures.
The retry mechanism balances accuracy with efficiency considerations. If all retries fail, the pipeline logs the error along with the NLQ for further manual intervention [Section III.C]. This logging capability enables continuous system improvement by identifying patterns in generation failures and informing future hint curation processes.
Experimental Methodology and Evaluation
Dataset Selection and Characteristics
The evaluation of HI-SQL covers multiple challenging datasets that represent different aspects of Text-to-SQL complexity. The BIRD dataset’s development set comprises 1,534 samples, each pairing natural language questions with corresponding SQL queries. This set spans various databases, including domains such as healthcare, finance, and education, among others [Section IV.A]. The diversity of domains ensures comprehensive evaluation across different database schema types and query patterns.
The complexity distribution within evaluation datasets reflects real-world query requirements. The SQL queries in the BIRD dataset range from simple to highly complex, requiring models to handle intricate query structures such as advanced joins, recursive patterns, and multi-step aggregations. This makes BIRD a demanding benchmark for evaluating and enhancing text-to-SQL model capabilities [Section IV.A]. This complexity distribution provides meaningful insights into system performance across different difficulty levels.
The SPIDER dataset is a large-scale, human-annotated resource for complex, cross-domain text-to-SQL tasks. It comprises over 10,000 natural language questions and 5,600 unique SQL queries across 200 databases spanning 138 domains [Section IV.A]. However, the research team identified a specific limitation in the dataset for evaluating complex query generation capabilities.
Most queries in the dataset are not complex enough to require joins, nested conditions, or other multi-table operations. Since our pipeline focuses on solving complex queries, we filter out only those complex queries from the SPIDER dataset that involves multi-table operations. In total we identify 84 such queries within the entire SPIDER dataset for our experiments [Section IV.A]. This filtering approach ensures that evaluation focuses on the types of queries where HI-SQL’s approach provides the greatest benefit.
Evaluation Metrics and Experimental Setup
The evaluation methodology emphasizes practical correctness over syntactic similarity. We use Execution Accuracy (EA) as the metric to evaluate the performance of our method. Execution Accuracy measures the correctness of the SQL outputs by comparing the results of the predicted queries against those from ground-truth queries when executed on respective database instances [Section IV.A]. This metric provides the most meaningful assessment of query generation quality.
This metric provides a comprehensive assessment by accounting for variations in valid SQL queries that can yield identical results for a given question [Section IV.A]. The execution accuracy approach recognizes that multiple syntactically different SQL queries may produce equivalent results, focusing evaluation on functional correctness rather than exact textual matching.
The experimental configuration ensures reproducible and fair comparisons across different approaches. For the hint curation, SQL query generation, and SQL verification processes, we utilize OpenAI’s GPT-4o with a temperature setting of 0.3 to control the randomness of the generated output [Section IV.B]. This configuration balances creativity with consistency in query generation.
The hint generation process involves a single call to the LLM to extract relevant hints for a specific database. The verification pipeline includes a feedback loop with a maximum of 3 retries (C = 3) [Section IV.B]. This setup ensures efficient processing while providing adequate opportunity for error correction.
Baseline Comparisons and Benchmarking
The evaluation includes comprehensive comparisons with established state-of-the-art methods. We conduct a baseline experiment without utilizing the generated hints. In this experiment, the NLQ and the entire schema of the corresponding database are passed to the LLM, and the output SQL query is obtained [Section IV]. This baseline comparison isolates the contribution of the hint generation mechanism.
Due to the large context window of modern LLMs we do not perform schema filtering and linking [Section IV]. This approach ensures fair comparison by providing both baseline and HI-SQL systems with complete schema information, allowing the evaluation to focus specifically on the impact of historical query hints.
The comparison with CHESS provides insight into multi-step system performance. CHESS is recognized as the top-performing open-source pipeline in the BIRD benchmark and employs multiple LLM calls along with self-verification unit tests to handle complex SQL query generation [Section IV]. This comparison demonstrates the effectiveness of single-step hint-enhanced generation versus complex multi-step approaches.
Results Analysis and Performance Insights
Quantitative Performance Improvements
The experimental results demonstrate substantial improvements across multiple evaluation metrics and datasets. On the BIRD dataset, HI-SQL attains a total execution accuracy of 62.38%, outperforming the baseline’s 54.1%. When analyzing query complexities, HI-SQL exhibits gains of 8%, 14%, and 15% in Simple, Moderate, and Challenging categories, respectively [Section V]. These improvements show consistent enhancement across different levels of query complexity.
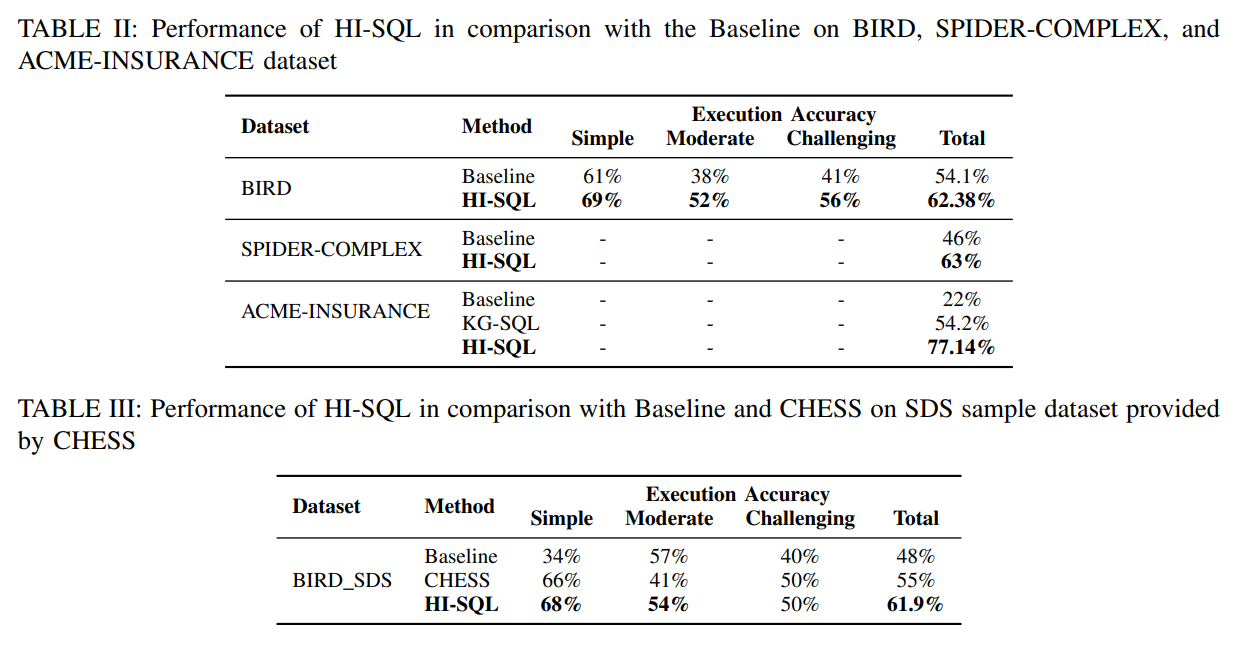
The performance gains become more pronounced with increasing query complexity, suggesting that the hint mechanism provides particular value for challenging database operations. Similar trends are observed for SPIDER-COMPLEX and ACME-INSURANCE datasets, where HI-SQL achieves total execution accuracies of 63% and 77.14%, surpassing the baseline of 17% and 55%, respectively [Section V]. The substantial improvement on the ACME-INSURANCE dataset demonstrates effectiveness in domain-specific enterprise scenarios.
Comparison with specialized domain approaches reveals the versatility of the HI-SQL method. Comparison results demonstrate that HI-SQL outperforms KG-SQL, achieving a higher accuracy of 77.14% compared to 54.2% [Section V]. This result is particularly significant because KG-SQL represents a knowledge-graph-enhanced approach specifically designed for the ACME-Insurance domain.
Computational Efficiency Analysis
The computational efficiency advantages of HI-SQL become apparent when analyzing the number of large language model calls required for query generation. The number of LLM calls in CHESS is M × K × N; where M represents the number of unit tests, K is the number of queries generated per turn, and N is the total number of natural language queries [Section V]. This multiplicative relationship creates substantial computational overhead for complex multi-step systems.
In contrast, our system is more efficient. We generate just one LLM call for hint generation across the entire database. If any query is invalid, the SQL verifier triggers one additional LLM call to rewrite the query. Additionally, our system requires one LLM call for each user-provided natural language query [Section V]. This linear scaling represents a fundamental efficiency advantage over multiplicative approaches.
The total number of LLM calls in our system is (C × N) + (1 × S), where C is the number of self-verifications, N is the total number of natural language queries, and S is the number of SQL re-generations (if required) for hints [Section V]. This formulation demonstrates the system’s efficient resource utilization while maintaining high accuracy levels.
Qualitative Query Improvement Analysis
The qualitative analysis reveals specific patterns in query improvement achieved through hint integration. The analysis of SQL query corrections reveals consistent patterns that enhance efficiency, accuracy, and clarity in query design. Common improvements include replacing subqueries with joins, which streamlines execution by reducing redundancy and introducing explicit aggregation and sorting to ensure clarity in computation and ordering logic [Section V].

The systematic nature of improvements suggests that hints provide structured guidance for query optimization. Queries were further simplified by removing unnecessary columns and computations, improving readability and performance. Semantic alignment was achieved by refining filtering conditions to match dataset characteristics, while null checks were added to prevent errors from missing values [Section V]. These improvements demonstrate the system’s ability to generate not just correct but optimized SQL queries.
Clear and consistent aliasing improved query readability, and string operations were optimized to reduce computational overhead. By analyzing historical query patterns, relationships, and data structures, hints provide the model with contextual guidance that aligns with the schema and query intent [Section V]. This alignment between hints and schema structure represents a key factor in the system’s effectiveness.
Comparative Analysis with State-of-the-Art Methods
Multi-Step System Limitations
Contemporary Text-to-SQL systems frequently employ multi-step architectures that introduce significant computational and reliability challenges. While these approaches have demonstrated effectiveness in improving query accuracy, they also lead to increased computational overhead due to the necessity of chaining multiple LLM calls [Section I]. These systems typically involve separate phases for schema analysis, entity linking, query generation, and verification, with each phase requiring independent large language model calls. The multiplicative nature of computational requirements creates scalability issues for real-world deployment scenarios.
The error propagation problem in multi-step systems represents a fundamental reliability concern. This results in high token usage and latency, while also making the system vulnerable to error propagation, as inaccuracies in one stage can negatively impact subsequent steps, ultimately compromising the system’s reliability [Section I]. When early stages in the processing pipeline produce incorrect outputs, these errors cascade through subsequent stages, often resulting in completely incorrect final queries. This cascading failure mode makes multi-step systems inherently less reliable than single-step approaches, particularly for complex queries where multiple processing stages may introduce errors.
Resource utilization in multi-step systems scales poorly with query complexity and database size. Recent efforts have focused on leveraging LLMs to address these issues by designing agentic systems that combine multi-step processes with verification methods for generating SQL queries [Section I]. Each additional processing step requires full model inference, creating substantial computational overhead. In enterprise environments where thousands of queries may require processing daily, this multiplicative resource requirement becomes prohibitively expensive and creates significant latency issues for interactive applications.
Single-Step Enhancement Benefits
The HI-SQL approach demonstrates that single-step processing enhanced with contextual hints can achieve superior performance compared to complex multi-step architectures. These hints are seamlessly integrated into the SQL generation process, eliminating the need for costly multi-step approaches and reducing reliance on human-crafted prompts [Abstract]. By providing comprehensive context including database schema, natural language queries, and relevant historical patterns, the system enables large language models to generate accurate SQL queries in a single inference step.
The hint integration approach provides several advantages over traditional schema linking and entity disambiguation stages. We introduce HI-SQL – a system that leverages historical query logs to enhance the Text-to-SQL translation process [Section I]. Rather than attempting to filter schema information or identify relevant entities through separate processing steps, the system provides complete context while using hints to guide the model’s attention toward relevant patterns and relationships.
The computational efficiency of single-step processing becomes particularly apparent in scenarios requiring high throughput query generation. This targeted approach directly addresses one of the primary weaknesses of LLM-generated queries — handling complex database operations — while simplifying the overall system architecture and improving efficiency [Section I]. The linear scaling of computational requirements with the number of queries enables practical deployment in enterprise environments where multi-step approaches would be prohibitively expensive or slow.
Domain Adaptation Capabilities
HI-SQL demonstrates strong performance across diverse database domains without requiring domain-specific customization or training. We rigorously evaluate our approach across multiple benchmarks, including SPIDER, BIRD, and ACME Insurance, to assess its effectiveness in diverse scenarios [Section I]. The system’s ability to achieve 77.14% execution accuracy on the ACME-Insurance dataset, compared to 54.2% for the specialized KG-SQL approach, illustrates the effectiveness of pattern-based learning over domain-specific knowledge engineering.
The approach’s domain adaptation capabilities stem from its reliance on learned patterns rather than manually crafted domain knowledge. Experimental results reveal substantial improvements over baseline models, and results comparable to open-source state-of-the-art methods in the respective benchmarks [Section I]. Historical query analysis automatically captures domain-specific patterns and relationships, enabling the system to adapt to new database schemas and domains without extensive manual configuration or ontology development.
The scalability of the approach across different database sizes and complexity levels provides practical advantages for enterprise deployment. Our solution achieves better query accuracy while reducing computational expenses by minimizing the number of LLM calls required, making it an efficient alternative to existing state-of-the-art methods [Section I]. Unlike systems that require manual schema linking or domain-specific prompt engineering, HI-SQL can be applied to new databases with minimal configuration, requiring only the collection of representative historical queries for hint generation.
Technical Implications and Future Directions
Scalability Considerations
The scalability characteristics of HI-SQL provide significant advantages for enterprise deployment scenarios. We introduce an automatic hint generation mechanism using historical query logs to improve SQL generation for complex queries [Section I]. The system’s linear computational scaling enables processing of large query volumes without the exponential resource growth associated with multi-step approaches. This scalability advantage becomes particularly important in interactive database applications where response time requirements are critical.
The hint generation process exhibits favorable scaling properties with respect to database size and complexity. The main contributions of this work are two-fold viz: (i). We introduce an automatic hint generation mechanism using historical query logs to improve SQL generation for complex queries; and (ii). We present a SQL generation pipeline that reduces computational cost and latency by minimizing LLM calls while maintaining accuracy comparable to the state-of-the-art methods [Section I]. Since hint generation is performed once per database and can be updated periodically, the computational overhead amortizes across all queries processed for that database. This approach contrasts favorably with systems requiring real-time schema analysis or entity linking for each query.
The system’s ability to handle complete database schemas without requiring filtering or preprocessing provides practical advantages for complex enterprise databases. These contributions underscore the importance of leveraging historical data insights for developing more efficient, accurate, and scalable Text-to-SQL systems, offering promising directions for future research in natural language interfaces for databases [Section I]. Many real-world databases contain hundreds of tables with thousands of columns, making schema filtering approaches error-prone and potentially eliminating critical information required for accurate query generation.
Integration with Modern Database Systems
HI-SQL’s architecture enables seamless integration with contemporary database management systems and cloud-based data platforms. In this paper, we propose HI-SQL – a system that leverages historical query logs to enhance the Text-to-SQL translation process [Section I]. The system’s reliance on standard SQL execution for verification ensures compatibility with diverse database engines, from traditional relational systems to modern cloud data warehouses.
The approach’s independence from specific database vendors or SQL dialects provides flexibility for multi-database enterprise environments. Experimental evaluations on multiple benchmark datasets demonstrate that our approach significantly improves query accuracy of LLM-generated queries while ensuring efficiency in terms of LLM calls and latency, offering a robust and practical solution for enhancing Text-to-SQL systems [Abstract]. Organizations frequently operate heterogeneous database environments with different systems for operational, analytical, and archival workloads. HI-SQL’s pattern-based approach enables consistent query generation across these diverse environments.
The system’s verification mechanism provides robust error handling that integrates naturally with database error reporting systems. Our method significantly reduces manual effort and enhances scalability and adaptability across various database environments [Section I]. The ability to capture and learn from query execution errors enables continuous improvement of hint generation and query optimization over time.
Research and Development Opportunities
The success of HI-SQL opens several promising research directions for advancing Text-to-SQL systems. Despite the current advancement, challenges remain in handling highly complex queries and improving efficiency. Our work addresses these gaps by leveraging historical query logs to generate contextual hints, enhancing accuracy, and reducing computational costs in Text-to-SQL systems [Section II]. The pattern-based approach to query generation could be extended to incorporate additional types of contextual information, such as query performance characteristics, data quality indicators, and user preferences.
The hint generation mechanism could be enhanced through more sophisticated analysis of historical query patterns, potentially incorporating machine learning techniques to identify optimal hint selection strategies. Text-to-SQL generation has evolved significantly, transitioning from early sequence-to-sequence models to advanced transformer-based architectures [Section II]. Advanced pattern recognition could identify subtle relationships between query types and optimal SQL generation approaches.
The integration of HI-SQL with automated database tuning and optimization systems presents opportunities for comprehensive query lifecycle management. Transformer-based models have played a pivotal role in advancing Text-to-SQL parsing [Section II]. By combining accurate query generation with performance optimization, future systems could provide end-to-end query processing solutions that consider both correctness and efficiency.
Practical Implementation Considerations
Deployment Architecture Requirements
Implementing HI-SQL in production environments requires careful consideration of infrastructure and architectural requirements. For hint generation purposes, we used 20% of samples from each dataset while excluding these samples from test sets when computing Execution Accuracy [Section IV.B]. The system’s computational requirements center around large language model inference capabilities, requiring adequate GPU resources or cloud-based model serving infrastructure. The single-step processing approach reduces overall computational requirements compared to multi-step alternatives while maintaining high accuracy.
The hint generation process requires periodic updating to maintain effectiveness as database schemas evolve and new query patterns emerge. For the hint curation, SQL query generation, and SQL verification processes, we utilize OpenAI’s GPT-4o with a temperature setting of 0.3 to control the randomness of the generated output [Section IV.B]. Organizations should plan for regular hint regeneration cycles that incorporate recent query logs and schema changes. This maintenance process ensures that the system continues to provide relevant guidance for query generation as business requirements evolve.
Database connectivity and security considerations require careful planning for production deployment. The hint generation process involves a single call to the LLM to extract relevant hints for a specific database. The verification pipeline includes a feedback loop with a maximum of 3 retries [Section IV.B]. The system requires read access to database schemas and the ability to execute generated queries for verification purposes. Security frameworks should ensure that the system operates with appropriate access controls while maintaining the ability to validate query correctness through execution.
Performance Monitoring and Optimization
Production deployment of HI-SQL requires comprehensive monitoring of query generation accuracy, system performance, and resource utilization. All the experiments were evaluated against the 80% held-out samples in each dataset [Section IV.B]. Organizations should establish baseline performance metrics and track improvements over time as the hint database grows and becomes more representative of actual query patterns.
The system’s verification mechanism provides valuable feedback for performance optimization and system tuning. This retry mechanism ensures that if the query is consistently re-generated incorrectly, the process terminates after C attempts [Section IV.B]. Query generation failures and retry patterns can inform adjustments to hint selection strategies and prompt engineering approaches. This feedback loop enables continuous improvement of system performance without requiring extensive manual intervention.
Resource utilization monitoring becomes particularly important for organizations processing large volumes of queries daily. To compare our method with another open-source SOTA method, we utilize a subsample of the BIRD dataset SDS provided by CHESS [Section IV.A]. The system’s linear scaling characteristics should be validated in production environments to ensure that performance expectations align with actual deployment requirements and usage patterns.
Integration with Existing Workflows
HI-SQL integration with existing database development and analytics workflows requires consideration of current tooling and processes. HI-SQL was evaluated against CHESS on the BIRD SDS dataset. Here, HI-SQL achieves a total execution accuracy of 61.9%, surpassing CHESS’s performance of 55% [Section V]. The system can complement existing database development tools by providing automated query generation capabilities while preserving existing quality assurance and testing procedures.
The approach’s compatibility with standard SQL enables integration with existing database administration and monitoring tools. Notably, HI-SQL demonstrates a significant improvement of 13% in Moderate complexity queries, showcasing its robustness in handling intermediate-level challenges [Section V]. Generated queries can be processed through existing performance analysis and optimization workflows, ensuring that automated query generation does not bypass established database management practices.
Training and adoption considerations require planning for user education and change management. By analyzing historical query patterns, relationships, and data structures, hints provide the model with contextual guidance that aligns with the schema and query intent [Section V]. While HI-SQL simplifies query generation for end users, database administrators and developers may need training on system capabilities, limitations, and best practices for effective utilization.
Conclusion
HI-SQL represents a significant advancement in Text-to-SQL generation technology, demonstrating that historical query analysis can provide substantial improvements in query accuracy while reducing computational overhead. The experimental evaluation underscores the efficacy and efficiency of HI-SQL in generating accurate and optimized SQL queries across diverse datasets and query complexities [Section VI]. The system’s single-step approach enhanced with contextual hints provides a practical alternative to complex multi-step architectures.
By leveraging a streamlined feedback loop and reducing the number of LLM calls, HI-SQL achieves significant computational efficiency compared to CHESS and other baseline methods [Section VI]. This efficiency advantage, combined with superior accuracy performance, positions HI-SQL as a viable solution for enterprise deployment scenarios where both cost-effectiveness and accuracy are critical requirements.
HI-SQL’s intelligent hint curation and correction mechanisms ensure semantic alignment with database schemas, enhancing query clarity, performance, and execution accuracy [Section VI]. The system’s ability to automatically adapt to new database schemas and query patterns provides practical advantages for organizations with evolving data requirements and complex database environments.
Unlike current systems that, once deployed, have no scope for improvement, our pipeline can utilize historical query logs to come up with new hints and thus adapt to give higher performance [Section VI]. This adaptive capability ensures that the system becomes more effective over time as it processes more queries and learns from additional patterns in database usage.
The research demonstrates that leveraging historical query patterns represents a promising direction for advancing Text-to-SQL systems beyond current state-of-the-art approaches. The combination of automated hint generation, single-step processing, and robust verification provides a foundation for practical database query automation that can scale to meet enterprise requirements while maintaining high accuracy standards.
References
Academic Papers and Research
- Talaei, S., Pourreza, M., Chang, Y. C., Mirhoseini, A., & Saberi, A. (2024). Chess: Contextual harnessing for efficient sql synthesis. arXiv preprint arXiv:2405.16755.
- Deng, N., Chen, Y., & Zhang, Y. (2022). Recent advances in text-to-SQL: a survey of what we have and what we expect. arXiv preprint arXiv:2208.10099.
- Li, J., Hui, B., Qu, G., Yang, J., Li, B., Li, B., Wang, B., Qin, B., Geng, R., Huo, N., Zhou, X. (2024). Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems.
- Shi, L., Tang, Z., Zhang, N., Zhang, X., Yang, Z. (2024). A survey on employing large language models for text-to-sql tasks. arXiv preprint arXiv:2407.15186.
- Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li, Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z. (2018). Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv preprint arXiv:1809.08887.
- Gao, D., Wang, H., Li, Y., Sun, X., Qian, Y., Ding, B., & Zhou, J. (2023). Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. Proceedings of the VLDB Endowment.
- Pourreza, M., Li, H., Sun, R., Chung, Y., Talaei, S., Kakkar, G. T., Gan, Y., Saberi, A., Ozcan, F., Arik, S. O. (2024). Chase-sql: Multi-path reasoning and preference optimized candidate selection in text-to-sql. arXiv preprint arXiv:2410.01943.
- Wang, B., Shin, R., Liu, X., Polozov, O., Richardson, M. (2019). Rat-sql: Relation-aware schema encoding and linking for text-to-sql parsers. arXiv preprint arXiv:1911.04942.
- Scholak, T., Schucher, N., Bahdanau, D. (2021). PICARD: Parsing incrementally for constrained auto-regressive decoding from language models. arXiv preprint arXiv:2109.05093.
- Zhong, V., Xiong, C., Socher, R. (2017). Seq2sql: Generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103.
- Xu, X., Liu, C., Song, D. (2017). Sqlnet: Generating structured queries from natural language without reinforcement learning. arXiv preprint arXiv:1711.04436.
- Yu, T., Li, Z., Zhang, Z., Zhang, R., Radev, D. (2018). TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation. arXiv preprint arXiv:1804.09769.
- Guo, J., Zhan, Z., Gao, Y., Xiao, Y., Lou, J. G., Liu, T., Zhang, D. (2019). Towards complex text-to-sql in cross-domain database with intermediate representation. arXiv preprint arXiv:1905.08205.
- Hwang, W., Yim, J., Park, S., Seo, M. (2019). A comprehensive exploration on wikisql with table-aware word contextualization. arXiv preprint arXiv:1902.01069.
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research.
- Min, S., Chen, D., Hajishirzi, H., Zettlemoyer, L. (2019). A discrete hard EM approach for weakly supervised question answering. arXiv preprint arXiv:1909.04849.
- Li, H., Zhang, J., Li, C., Chen, H. (2023). Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql. Proceedings of the AAAI Conference on Artificial Intelligence.
- Sequeda, J., Allemang, D., Jacob, B. (2024). A benchmark to understand the role of knowledge graphs on large language model’s accuracy for question answering on enterprise SQL databases. Proceedings of the 7th Joint Workshop on Graph Data Management Experiences & Systems.
- Li, J., Cheng, M., Liu, Q., Ni, P., Wang, J. (2024). CodeS: Towards Building Open-source Language Models for Text-to-SQL. arXiv preprint arXiv:2402.16347.
- Maamari, K., Abubaker, F., Jaroslawicz, D., Mhedhbi, A. (2024). The death of schema linking? text-to-sql in the age of well-reasoned language models. arXiv preprint arXiv:2408.07702.
Technical Articles and Blogs
- LLM text-to-SQL solutions: Top challenges and tips
- Build a robust text-to-SQL solution generating complex queries, self-correcting, and querying diverse data sources
- Introducing Select AI - Natural Language to SQL Generation on Autonomous Database
- Complete Guide to Database Schema Design
- NL2SQL Handbook: Continuously updated handbook for Text-to-SQL techniques